數據
摘要
為行政和臨床目的而收集的常規健康數據,沒有特定的先驗研究目標,越來越多地用於研究。這些數據的快速演變和可用性揭示了現有報告指南沒有解決的問題,如加強流行病學觀察性研究的報告(STROBE)。使用觀察常規收集的健康數據(RECORD)進行的研究報告(REporting of studies)聲明的創建就是為了填補這些空白。RECORD的創建是對STROBE聲明的擴展,以處理使用常規收集的健康數據的觀察性研究的特定報告項目。RECORD包含13項清單,涉及文章的標題、摘要、引言、方法、結果和討論部分,以及納入此類研究報告所需的其他信息。本文檔包含清單和解釋性和詳細說明信息,以加強清單的使用。每個RECORD檢查清單項目的良好報告的例子也包括在這裏。本文件,以及附帶的網站和留言板(http://www.record-statement.org),將加強對RECORD的實施和理解。通過實施RECORD,作者、期刊編輯和同行審稿人可以鼓勵研究報告的透明度。
引用:Benchimol EI, Smeeth L, Guttmann A, Harron K, Moher D, Petersen I, et al.(2015)使用觀察性常規收集健康數據(RECORD)聲明進行的研究報告。公共科學學報12(10):e1001885。https://doi.org/10.1371/journal.pmed.1001885
發表:2015年10月6日
版權:©2015 Benchimol等人。這是一篇開放獲取的文章創作共用授權協議它允許在任何媒體上無限製地使用、分發和複製,前提是注明原作者和來源
資助:加拿大衛生研究院(批準號130512)、瑞士國家科學基金會(批準號IZ32Z0_147388 / 1)和奧胡斯大學臨床流行病學係。資助方在研究設計、數據收集和分析、出版決定或稿件準備方麵沒有任何作用。
利益衝突:DM是《公共科學圖書館·醫學》編輯委員會成員。其他作者沒有利益衝突需要聲明。
縮寫:臨床實踐研究數據鏈;全科醫學研究數據庫;HSMR,醫院標準化死亡率;國際疾病分類;ISC,新南威爾士州住院病人統計資料收集;MDC,新南威爾士州助產士數據收集;MeSH,醫學學科標題;移動健康應用,移動健康應用;國民保健服務;非小細胞肺癌; PET, positron emission tomography; PICANet, Paediatric Intensive Care Audit Network; RECORD, REporting of studies Conducted using Observational Routinely collected health Data; SEER, Surveillance, Epidemiology, and End Results; SNIIRAM, Système national d'informations inter régimes de l'Assurance maladie; STROBE, Strengthening the Reporting of Observational Studies in Epidemiology
出處:不是委托;外部同行評議
簡介
在衛生保健提供過程中以及通過監測疾病發病率和結果產生的數據的日益可用性已經改變了研究前景。例行收集的健康數據定義為收集的數據,在用於研究之前未製定特定的先驗研究問題[1].這些數據源可包括為研究(如疾病登記)、臨床管理(如初級保健數據庫)、衛生係統規劃(如衛生行政數據)、臨床護理記錄(如電子健康記錄數據庫)或流行病學監測(如癌症登記和公共衛生報告數據)提供廣泛的資源。這些數據產生於各種衛生保健環境和地理位置,為創新、高效和具有成本效益的研究提供了機會,為臨床醫學、衛生服務規劃和公共衛生方麵的決策提供信息[2].在國際上,各國政府和供資機構已優先使用常規收集的衛生數據作為工具,以改善患者護理、轉變衛生研究和提高衛生保健效率[3.].
雖然數據可用性的爆炸式增長為回答緊迫的研究問題提供了重要的機會,但它也給那些開展、評估研究和實施研究結果的人帶來了挑戰。常規收集的衛生數據來源範圍廣泛,該領域迅速擴大,因此很難確定個別數據來源的長處、局限性和相關偏差。基於常規收集數據的研究報告的不完整或不充分加劇了這些挑戰。對利用常規數據來源的研究樣本進行係統分析,發現了報告不完整或不清楚的各種領域[4].報告缺陷包括有關暴露和結果編碼的信息不充分或缺失,以及不同數據源的鏈接率細節。最近的兩項係統綜述也記錄了驗證常規數據源數據的研究報告不佳[5,6],這可能會模糊偏見的來源,阻礙進行元分析的努力,並導致錯誤的結論。
已經製定了報告指南,以指導針對一係列研究設計和背景的報告,並與報告質量的提高相關[8,9].加強流行病學觀察性研究報告(STROBE)聲明的製定是為了提高觀察性研究報告的透明度[10,11,並被主要醫學期刊廣泛采用和認可。事實證明,在編輯過程中實施該方法可以提高研究報告的質量[12,13].大多數使用常規收集的數據進行的研究在設計上是觀察性的,因此,STROBE指南是相關的和適用的。然而,由於STROBE聲明被設計用於所有的觀察性研究,因此與使用常規收集的數據報告研究相關的具體問題沒有得到解決。在2012年倫敦初級保健數據庫研討會之後,一個對使用常規收集的健康數據特別感興趣的國際科學家小組和STROBE小組的代表舉行了會議,在使用常規收集的健康數據的研究背景下討論STROBE [14,15].在使用這些數據源的研究中,發現了STROBE的重要差距,並達成了對STROBE進行擴展的協議。因此,使用觀察性常規收集數據進行的研究報告(RECORD)倡議被建立為一個國際合作進程和STROBE的擴展,以探索和解決與使用常規收集的健康數據進行的研究相關的具體報告問題。RECORD計劃涉及了100多個國際利益攸關方,包括研究人員、期刊編輯和數據消費者,包括那些利用常規數據的研究結果為決策提供信息的人。製定記錄指引所用的方法詳列於其他地方[16],並根據既定方法製訂報告指引[17].簡而言之,對利益相關者進行了兩次調查,以確定將納入RECORD聲明的主題並確定其優先次序。一個工作委員會隨後親自開會確定了聲明的措辭。利益相關者審查了報表並提供了反饋。最後的清單和本解釋性文件由指導委員會的成員起草,並由工作委員會審查和批準。STROBE指導委員會的成員參與了RECORD的創建。
與STROBE方法一致,RECORD指南不是為了推薦用於進行研究的方法,而是為了改進其報告,以確保讀者、同行審稿人、期刊編輯和其他研究的消費者能夠評估其內部和外部的有效性。通過使用常規收集的健康數據改進研究報告的質量,我們尋求減少不明確的研究報告,並實現科學過程的原則:發現、透明和可複製性[18].
記錄清單中的項目
完整的記錄清單載於表1.由於RECORD是可用的STROBE項目的擴展,陳述被呈現在相應的STROBE清單項目旁邊,按稿件部分組織。我們建議作者充分處理清單中的每一項,但不規定在稿件中的精確順序或位置。下麵我們為每個RECORD清單項目提供了解釋性文本,按稿件部分組織。如果不需要額外的檢查清單項目將STROBE擴展到使用常規收集的健康數據的研究,則在相應的STROBE項目下提供所需的任何解釋。
標題和摘要
記錄項目1.1:使用的數據類型應在標題或摘要中命名。在可能的情況下,應包括所用數據庫的名稱。
記錄項目1.2:如果適用,應在標題或摘要中報告研究發生的地理區域和時間框架。
記錄項目1.3:如果為研究進行了數據庫之間的鏈接,應在標題或摘要中明確說明。
解釋。
由於沒有公認的醫學主題標題(MeSH)用於識別使用常規收集的健康數據的研究,因此能夠識別使用此類數據進行的研究是很重要的。但是,考慮到數據類型的多樣性,僅僅說明使用了常規數據是不夠的。相反,例程數據的類型應該在標題和/或摘要中指定。數據類型的例子包括衛生行政數據、其他行政數據(例如,保險、出生/死亡登記處和就業)、疾病登記處、初級保健數據庫、電子健康記錄數據和人口登記處。命名所使用的數據庫很重要,但不能取代在標題或摘要中提供數據源的類型。
地理區域和時間範圍是包含在STROBE清單中的項目。我們建議這一信息也是使用RECORD檢查表的稿件標題或摘要部分的必要項目。顯然,區域和時間框架的報道範圍需要遵守字數限製,並考慮到保密問題。然而,地區應至少報告用於定義研究人口的最大地理層次(例如,民族、州、省和地區)。
此外,數據庫之間的鏈接(如果進行了)應在標題或摘要中報告。可接受的措辭包括“使用多個鏈接的衛生管理數據庫”或“(數據庫名稱)鏈接到(數據庫名稱)”。在標題或摘要中使用“鏈接”或“鏈接”提供足夠的信息;關於鏈接方法的進一步細節應在稿件的方法一節中提供。
簡介
除了STROBE項目外,不需要任何特定於RECORD指南的項目。STROBE指南建議“具體的目標,包括任何預先指定的假設,”應在引言部分說明。說明具體的研究目標對於任何觀察性研究的複製和翻譯都是必不可少的。對於使用常規收集的數據的研究,作者應進一步澄清分析是否具有探索性,目的是在數據中發現新的關係(例如數據挖掘或產生假設的研究[21,22])或驗證,以檢驗一個或多個假設[23].作者還應該說明他們的假設是在數據分析之前還是之後產生的。他們應該清楚地說明是否有研究協議,如何訪問該協議,以及研究是否在公開可訪問的研究注冊中心注冊。由於使用常規收集的數據進行研究的方法的優點和局限性可能存在爭議,因此對研究目標的明確描述是必要的[23,24].僅僅將一項研究貼上描述性的標簽而不明確其目的是產生或檢驗一種假設是不夠的。
方法(設置)
不需要額外的RECORD項目來擴展STROBE要求以“描述設置、地點和相關日期,包括招募、曝光、跟蹤和數據收集期間”。作者應注意,除了在標題和/或摘要中已經提及的數據庫類型之外,還應提供信息,使讀者能夠了解數據庫的內容和有效性,以及收集數據的原始原因。例如,專家或初級保健醫生、門診或住院護理,或高級醫生或醫科學生都可以使用電子健康記錄。用戶可以接受詳盡和可重複的數據輸入方麵的專門培訓,也可以不提供培訓[25].作者還應該描述數據庫總體與源總體的關係,包括選擇標準,以便讀者確定結果是否可以應用於源總體。
方法(參與者)
記錄項目6.1:應詳細列出研究人群選擇的方法(如用於確定受試者的代碼或算法)。如果這是不可能的,則應提供解釋。
記錄項目6.2:應參考用於選擇種群的代碼或算法的任何驗證研究。如果本研究進行了驗證,但沒有在其他地方發表,則應提供詳細的方法和結果。
記錄項目6.3:如果研究涉及數據庫的鏈接,考慮使用流程圖或其他圖形顯示來演示數據鏈接過程,包括在每個階段擁有鏈接數據的個體數量。
的例子。
6.1記錄項。以下摘錄提供了一個良好報告的例子:
OCCC[安大略克羅恩和結腸炎隊列]使用經過驗證的算法來基於年齡組識別IBD患者。每個算法都在安大略省進行了驗證,在其應用的特定年齡組中,在多個隊列中,醫療實踐類型和地區。對於18歲以下的兒童,算法由他們是否接受結腸鏡檢查或乙狀結腸鏡檢查來定義。如果他們做過內窺鏡檢查,兒童在3年內需要4次門診醫生接觸或2次IBD住院治療。如果他們沒有接受內窺鏡檢查,兒童在3年內需要7次門診醫生接觸或3次IBD住院治療。該算法正確識別出患有IBD的兒童,靈敏度為…26].
這篇文章引用了兩個以前的算法驗證研究,以識別不同年齡的炎症性腸病患者,包括診斷準確性的測量。
記錄項目6.2:Ducharme和同事在他們的文章中詳細描述了識別腸套疊兒童的代碼驗證,然後使用驗證的代碼描述流行病學。參與驗證研究的代碼列於文章的圖2 [27].2.在他們的文章中,Benchimol和同事沒有進行驗證工作;然而,引用了之前進行的驗證工作。詳細描述了識別算法代碼的診斷準確性[26].
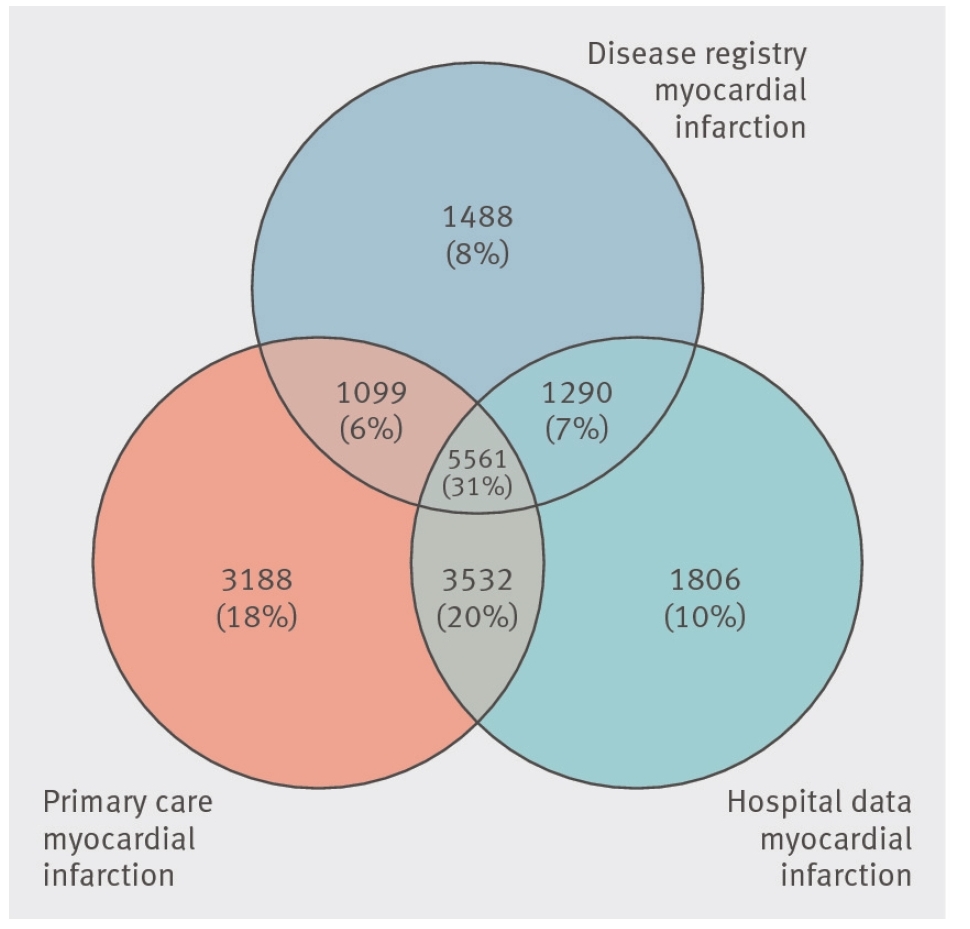
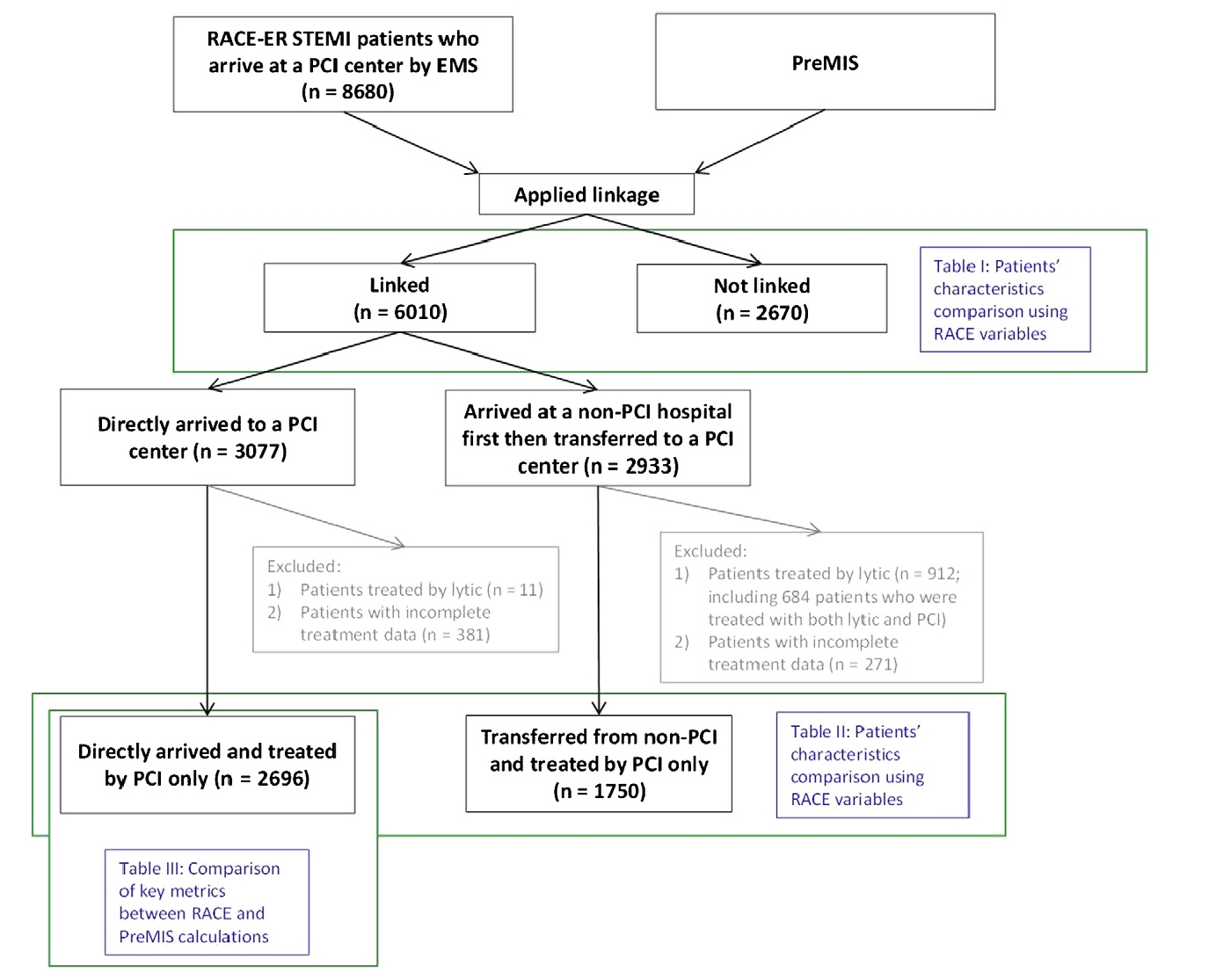
RECORD ITEM 6.3:在RECORD網站上的示例圖2、圖3和圖4中演示了一些說明鏈接過程的可能方法:
圖2。圖解來說明鏈接過程(轉載自Herrett等人的許可。[28]瀏覽我們的網頁:http://record-statement.org/images/figure2.jpg).
{kind=link}
圖3。說明聯動過程的混合流程圖和維恩圖(經van Herk-Sukel等人許可轉載)[29]瀏覽我們的網頁:http://record-statement.org/images/figure3.jpg).
{kind=link}
圖4。聯動圖結合參與者流程圖(經Fosbøl等人授權轉載)[30.]瀏覽我們的網頁:http://record-statement.org/images/figure4.jpg).
{kind=link}
解釋。
記錄項目S 6.1和6.2:報告用於獲得研究人群的識別代碼/算法的有效性對使用常規收集的健康數據的觀察性研究報告的透明度至關重要。此外,代碼/算法的報告允許其他調查人員參與外部或內部驗證。
用於識別研究對象的方法應該明確和清楚地說明,包括識別是基於單個代碼、算法(記錄或代碼的組合)、數據庫之間的鏈接,還是自由文本字段。
與許多其他流行病學研究一樣,在使用常規健康數據的研究中存在錯誤分類偏見的風險,可能威脅到研究結果的有效性[31].盡管在使用包含大量人口的數據庫的研究中,錯誤分類的風險被放大,但此類研究提供了研究罕見或不常見疾病的機會[32].鑒定方法的驗證越來越受到重視,認為這對於使用常規收集的健康數據的研究至關重要,特別是對於使用為記賬目的收集的管理數據的研究中的疾病代碼[33].外部驗證研究通常需要將用於識別研究人群的代碼或算法與參考標準進行比較。最常見的參考標準是醫療記錄、病人或從業員的調查,以及臨床注冊表[5,34].此外,可對數據庫進行內部驗證,以比較單個數據庫內的重疊數據源[35].準確性的測量方法與診斷試驗研究中報道的類似,包括敏感性、特異性、陽性和陰性預測值或kappa係數[5,34].
因此,對於使用常規收集的健康數據的觀察性研究,我們建議在稿件的方法部分給出識別代碼/算法的外部或內部驗證的細節。如果以前進行過一個或多個驗證研究,則應引用這些驗證研究。如果沒有進行此類驗證研究,則應明確說明這一點。此外,還應簡要討論鑒定方法的準確性(使用常見的診斷準確性術語)及其在研究的亞人群中的功能。如果驗證工作是作為相關觀察性研究的一部分進行的,我們建議作者在驗證研究中使用已發表的報告指南[5].必須說明驗證是否發生在與本研究所選擇的不同的源或數據庫總體中,因為代碼在不同總體或數據庫中的功能可能不同[36].此外,如果所比較數據的參考標準存在已知的問題,例如不完整或不準確,應報告這些問題,並作為一種限製加以討論。作者應該討論使用所選代碼/算法來確定研究人群和結果的含義、錯誤分類的風險以及對研究結果的潛在影響。特別重要的是,要討論依賴於在不同人群中進行的驗證研究的影響。
流程圖或其他圖形顯示可以傳達有關聯動過程的有用信息,並可以簡化可能冗長的描述。這種插圖可以提供關鍵數據,例如有關有關聯和無關聯個體的比例和特征的信息。讀者應該能夠確定成功鏈接的數據庫人口的比例和結果研究人口的代表性。鏈接流程圖可以是獨立的圖(例如,維恩圖或流程圖),也可以與STROBE推薦的參與者流程圖結合。由於圖形顯示可以以多種格式提供,我們不推薦使用一種特定的格式。
方法(變量)
記錄項目7.1:應提供用於對暴露、結果、混雜物和效果修正物進行分類的代碼和算法的完整列表。如果這些代碼或算法不能報告,則應提供解釋。
解釋。
就像用於識別研究人群的代碼/算法一樣,用於對暴露、結果、混雜因素或效應修正因素進行分類的代碼/算法會使研究存在潛在的分類錯誤偏見。為了便於複製、評估和與其他研究進行比較,我們建議在手稿、在線附錄和/或外部網站中提供所有用於進行研究的診斷、程序、藥物或其他代碼的列表。對於由調查結果組成的常規數據,調查問題應提供與研究對象相關的精確措辭。考慮到所有研究中存在錯誤分類偏見的風險,包括使用常規健康數據進行的研究[31,作者應該提供足夠的細節,以使他們的研究具有可重複性,並使偏見的風險明顯。驗證研究可以在文章手稿中描述,也可以作為其他出版或在線材料的參考。如上所述,作者應說明驗證研究是否在與本研究中所檢查的不同的源或數據庫人群中進行。
我們認識到,在某些情況下,研究人員可能被禁止提供出版物中使用的代碼列表和算法,因為這些信息被認為是專有的或受版權、知識產權或其他法律保護。例如,盈利性公司創建了一些共病調整指數,並出售給研究人員,供學術研究使用[39,40].在這些情況下,作者可能依賴於數據提供者或可信的第三方來收集、清理和/或鏈接數據。作者應就其無法提供代碼列表或如何識別個人或條件的其他細節提供詳細解釋,並應努力包括對這些列表擁有所有權的團體的聯係信息。此外,作者應解決他們無法提供這些信息可能對研究複製和評估方麵的研究消費者造成的影響。最好的情況是,第三方應該提供關於如何收集、清理或鏈接數據的詳細信息。改善數據提供者和數據用戶之間的溝通可能是互利的。
一些人認為代碼列表代表了研究人員的知識產權。這些列表的發布可以允許其他研究人員將其用於自己的研究,從而剝奪了創建代碼列表的作者的知識產權和信譽。我們認為,這一觀點與允許複製研究的透明科學標準不一致。因此,除了受法律或合同保護的內容外,我們建議公布完整的代碼清單。
考慮到許多期刊的字數和空間限製以及代碼列表/算法的潛在長度,我們認識到在紙質期刊上發表文章可能是不可能的。相反,詳細的信息可以在文本中報告,發表的表格,期刊網站上的在線補充作為附錄,由作者或其他個人永久在線托管,或存入第三方數據存儲庫(例如,Dryad或Figshare)。手稿的文本和參考部分應該提供關於如何訪問代碼列表的詳細信息。像ClinicalCodes.org這樣的代碼存儲庫對於基於健康數據的研究中使用的代碼的文檔化和透明度有很大的希望[41].如果代碼列表發布在期刊網站的在線補充或作者提供的外部網站上,鏈接應該發布在主要期刊文章中。在期刊網站或PubMed Central上發表(http://www.ncbi.nlm.nih.gov/pmc/)增加了隻要雜誌在運作,增刊就可以使用的可能性。如果在外部私人或機構網站上發表是唯一的選擇,我們建議這些列表在期刊文章發表後至少10年內繼續可用。如果更改了URL地址,則需要從舊的web地址自動重定向。這些措施將允許本文的未來讀者訪問完整的代碼列表。
除了文章中提供的代碼列表(或在線附錄)之外,作者應該包括對研究中使用的代碼/算法的選擇是否可能導致偏見的反思。這種偏差可能包括錯誤分類偏差、確定偏差和由於數據缺失造成的偏差。如果基於不同的編碼/算法進行敏感性分析,也應該描述和評估這些。潛在偏差的討論也可以與RECORD和STROBE檢查表的其他部分聯係起來,如研究主題的選擇和代碼的驗證(或缺乏)。
方法(統計方法)
的例子。
記錄項目12.1:以下文章描述了對英國全科醫學研究數據庫(GPRD)子集的訪問。
- "大珠三角將通過醫學研究理事會許可證協議資助的項目的數據集限製在10萬人以內。這種限製要求進行病例對照而不是隊列設計,以確保我們針對每種特定症狀識別出足夠多的癌症病例……”[42].
- "根據醫學研究理事會的學術機構執照,從全科醫學研究數據庫中抽取了一份隨機樣本。[43].
記錄項12.2:以下是數據清理方法說明的示例[44]:
用於鏈接的通用標識符的完整性在數據集之間和隨著時間的變化而變化(標識符近年來更加完整)。對於LabBase2,標識符的完整性因單位而異(圖2)。對於PICANet[兒科重症監護審計網絡],出生日期和醫院編號100%完整,大多數其他標識符為>98%完整,除了NHS[國家衛生服務]編號(85%完整)。對於這兩個數據集,都進行了清理和數據準備:NHS或醫院編號,如“未知”或“9999999999”設置為空;通用名(例如,“Baby”,“Twin 1”,“Infant Of”)設置為null;為多個姓和名創建了多個變量;以“ZZ”開頭的郵政編碼(表示沒有英國郵政編碼)被設置為空。
記錄項目12.3:以下摘自文章的節選是良好報告數據聯係水平、使用的聯係技術和方法以及評價聯係質量的方法的好例子:
- "我們將活產和胎兒死亡證明與事件的時間鏈聯係起來,這些事件(不包括人工流產和異位妊娠)構成了個別婦女的生殖經曆" [45].
- 兩篇文章對專門為報告的研究進行的聯係進行了極好的描述[44,45].在Harron及其同事的文章中[44],詳細解釋了連杆,並提供了圖形演示的匹配過程。此外,還描述了計算鏈接概率的方法:“計算匹配概率P(M|一致模式),以估計在聯合標識符集上給定一致的匹配概率。這避免了標識符之間獨立的假設。概率是由鏈接數除以每個協議模式的總配對數得出的(基於訓練數據集中識別的可能鏈接)。例如,如果378對比較對出生日期和Soundex一致,但性別不一致,其中312對是可能鏈接,則一致模式[1,1,0]的匹配概率為312/378 = 0.825 " [44].Adams及其同事的文章還對鏈接過程進行了詳細的解釋:“確定性鏈接由第一階段組成,該階段包含六個處理步驟,在此過程中,鏈被形成,個體(以前未鏈接的)記錄被添加到鏈中。接下來是第n階段,這需要對文件進行多次傳遞,以合並屬於同一個母體的鏈。[45].
- 相比之下,如果一項研究引用之前的相關數據,引用之前的論文可能就足夠了,如下:“來自兩個數據庫的記錄根據出生日期、性別和郵政編碼鏈接到市政登記處,然後相互鏈接。該聯係由荷蘭統計局進行,並在以前的出版物中有所描述”[20.].
- 以下是一個良好報告關聯個體和非關聯個體特征的例子:“為了本文的目的,不匹配的ISC[住院患者統計收集]記錄將被稱為ISC殘差,不匹配的MDC[助產士數據收集]記錄將被稱為MDC殘差,鏈接對被稱為匹配記錄....選擇兩個數據集上可用的變量在三組之間進行比較——isc殘差、MDC殘差和匹配記錄”[46].
解釋。
記錄項目12.1和12.2:如果不熟悉隊列創建或研究目標的細微差別的數據分析師創建了研究隊列,則可能出現錯誤。因此,應該報告作者訪問數據庫的程度。在研究的不同階段,數據清理方法的描述應包括用於篩選錯誤和缺失數據的方法,包括範圍檢查、重複記錄檢查和重複測量的處理[47,48].報告的其他方法可包括評估頻率分布和數據交叉表格和圖形探索,或使用統計方法進行離群值檢測[49].可以提供關於錯誤診斷的進一步細節,包括合理性的定義和分析中的錯誤處理。清晰和透明地描述數據清理方法非常重要,因為方法的選擇可能會影響研究結果、研究的可重複性和研究結果的可重複性[50].
記錄項目12.3:對於連鎖研究,我們建議報告連鎖的估計成功率,確定性連鎖與概率連鎖的使用,連鎖所用變量的質量和類型,以及連鎖驗證的結果。如果專門為研究進行了跨數據庫記錄的鏈接,則應報告鏈接和鏈接質量評價方法,包括誰進行鏈接的信息。在可能的情況下,應提供關於阻塞變量、鏈接變量的完整性、鏈接規則、閾值和手動審查的詳細信息[44].如果聯接是在研究之前進行的(即為以前的研究或一般使用),或者如果數據聯接是由外部提供者進行的,例如數據聯接中心,則需要一份說明數據資源和聯接方法的參考資料。
描述鏈接方法和評價其成功的數據對於允許讀者評估任何鏈接錯誤和相關偏差的影響至關重要[51].具體來說,讀者應該知道所使用的鏈接類型是確定的和/或概率的,以便確定鏈接是否會受到假匹配或錯過匹配的影響。當不同數據源之間有唯一的標識符時,確定性鏈接非常有用。當這樣的標識符不可用時,對應用的記錄鏈接規則(或統計鏈接鍵)的描述是至關重要的。相比之下,概率鏈接使用多個標識符,有時具有不同的權重,匹配被認為高於特定的閾值。混合方法也可以使用。例如,確定性鏈接可能用於某些記錄,而當其他記錄的唯一標識符不可用時,則可能應用概率鏈接。當鏈接錯誤的概率(例如,錯誤和缺失匹配)和感興趣的變量之間存在關聯時,就會發生鏈接偏差。例如,連接率可能因患者特征(如年齡、性別和健康狀況)而異。連係過程中即使是很小的誤差也可能引入偏差,導致結果可能高估或低估所研究的關聯[52].作者應使用標準方法報告鏈接錯誤,包括與金標準或參考數據集的比較、敏感性分析以及比較鏈接和非鏈接數據的特征[53].報告鏈接錯誤可以讓讀者確定鏈接的質量和與鏈接錯誤相關的偏差的可能性。
結果(參與者)
記錄項目13.1:詳細描述本研究納入人員的選擇(即研究人群選擇),包括基於數據質量、數據可用性和聯係的篩選。入選人員的選擇可以在文本和/或通過研究流程圖的方式進行描述。
的例子。
下麵摘錄了一個良好報告的例子:
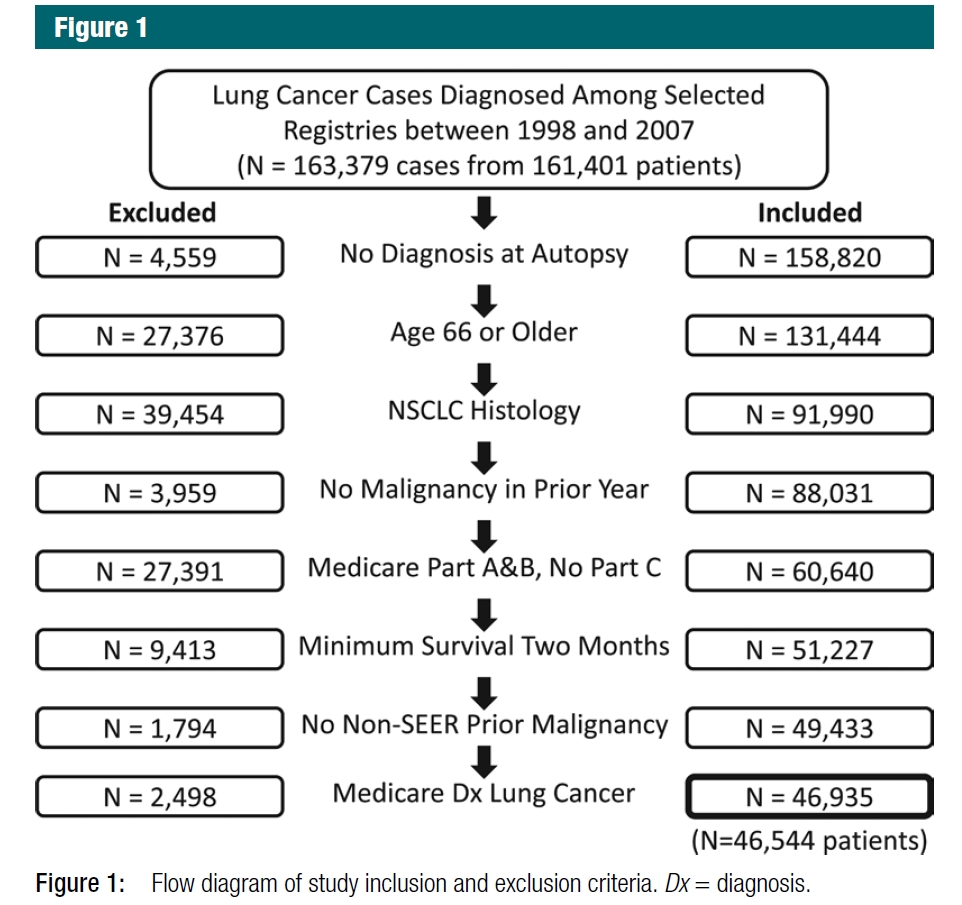
我們在1998年至2007年的SEER(監測、流行病學和最終結果)登記中確定了161,401名被診斷為一個或多個肺癌和支氣管癌病例的醫療保險受益人。在這些患者中,我們總共確定了163,379例獨立的肺癌診斷。(在研究期間,一些患者有兩例原發性肺癌,間隔超過一年)。圖1顯示了最終隊列46,544名患者的來源,其中有46,935例NSCLC[非小細胞肺癌][54].(參見圖5中的示例流程圖,可在http://record-statement.org/images/figure5.jpg.)
{kind=link}
解釋。
作者應明確說明從常規收集的原始健康數據數據庫中得到研究人群的來源,因為需要記錄研究人群和數據庫人群之間的差異,以便應用結果(另見RECORD項目6.1)。使用常規數據源的研究人員經常根據可用數據的質量等因素限製他們的研究人群。例如,他們可能會將研究周期限製在已知數據質量可接受的時間內,從而排除潛在參與者。研究可排除電子健康記錄條目不一致的醫療實踐,或等待這些實踐變得一致[38,55].根據數據的可用性,研究人群也可能受到限製。例如,在利用美國醫療保健數據的研究中,由於缺乏臨床事件記錄,目前在保健組織登記的受益人經常被排除在外[54,56].在使用資格隨時間波動的數據源(例如保險數據庫)時,研究人員需要明確說明如何定義資格以及如何在研究中管理資格的變化。如果一項研究使用了關聯的常規數據,則通過限製可獲得關聯數據的個體來減少研究人群[57].高度受限的隊列也可用於方法上的原因,以消除一些混淆的來源。
因此,獲得最終研究人群、納入和排除標準以及隊列創建和分析中不同階段的研究參與者的納入和排除的步驟應該在稿件中明確定義,要麼在文本中,要麼使用合適的流程圖。研究人群可以使用不同的代碼和/或算法(見RECORD項目6.1),隨著時間的推移,代碼的不同使用可能會影響研究人群[58,59].一些研究可能還使用了一些或多或少敏感/具體的案例定義,這可能會對後續的分析產生影響。這些步驟的描述對於評估研究結果的外部有效性和在某些情況下評估可能的選擇偏差是重要的。可能報告敏感性分析,以評估數據缺失的潛在影響和研究人群的代表性。提供關於從初始數據庫中選擇研究人群的信息也允許研究的複製。輔助分析可能已經在不同的研究人群中進行,並可能在在線附錄中報告。
討論(限製)
記錄項目19.1:討論使用非創建或收集的數據來回答特定研究問題的影響。包括對錯誤分類偏差、未測量混雜、缺失數據和隨時間變化的合格性的討論,因為它們與所報告的研究有關。
的例子。
下列文件說明了與使用行政數據有關的限製:
- “第三,這項研究是一項回顧性的、基於聲明的分析。在分析中隻能檢測到由醫療保險支付的PET(正電子發射斷層掃描)掃描。為了最大限度地減少漏報理賠的比例,所有分析都局限於在診斷前和診斷後的12個月內,既擁有醫療保險A部分和B部分的保險,又沒有加入管理式醫療或醫療保險C部分的醫療保險受益人。第四,SEER登記的患者更有可能是非白人,生活在貧困程度較低的地區,生活在城市地區,這可能限製了研究結果的可泛化性。第五,在研究期間,疾病分期基於超過4個月或第一次手術前獲得的SEER數據。2004年,SEER的數據收集改為協同分期係統。目前尚不清楚我們的結果與這種新方法有何不同。”54].
- “盡管SEER-Medicare數據有一些優勢,包括相對較大的樣本量、對美國人群的普遍性和處方的詳細信息,但我們的研究受到了限製,因為缺乏有關膽固醇、甘油三酯和葡萄糖水平的實驗室數據,這些數據可以告知人群代謝紊亂的程度……因此,基於實驗室的數據可以減少代謝疾病嚴重程度的殘留混雜。”我們還缺乏關於癌症進展的更詳細的數據,這可能會混淆他汀類藥物使用和死亡之間的關係,因為他汀類藥物治療可能會在預期生存時間較短的患者中被停止或停止。[60].
解釋。
常規健康數據的收集通常不考慮特定的先驗研究問題,收集數據的動機可能各不相同。許多潛在的偏倚領域,包括所有與觀察性研究相關的常見偏倚來源,也包括一些使用常規數據的觀察性研究的更具體的偏倚來源,危及研究人員的結論。作者應討論以下可能的偏倚來源:(1)識別研究人群、結果、混雜因素或效應修正因素(誤分類偏倚)的代碼或算法;(2)缺失變量(未測混雜);(3)缺失的數據;(4)資格隨時間的變化。
日常數據收集的基本原理可能會影響數據的質量和對研究問題的適用性。例如,用於回顧性分析的注冊表可能比收集其他類型例行數據的組織實施更好的質量控製,盡管這可能有所不同。類似地,一些管理數據受到嚴格的質量控製,而其他數據則沒有。管理數據在上編碼或機會編碼中特別容易出錯。例如,當醫院報銷是基於病例組合的複雜性時,醫院可以通過對患者記錄自由地應用更複雜的疾病代碼來最大化報銷[61].此外,編碼策略的更改可能會影響數據的有效性或一致性。例如,供應商計費激勵代碼的引入可能會隨著時間的推移改變代碼被使用的可能性[62,63].其他守則可因患者的汙名化或提供者的處罰而被避免[64].此外,代碼分類係統版本的更改(例如,從國際疾病分類(ICD)-9到ICD-10)可能改變使用編碼數據確定的有效性[65,66].不同醫院和人群的臨床實踐的差異可能會導致在特定地點和/或實踐中進行實驗室調查,這可能會影響診斷算法。如果存在任何這些潛在的錯誤分類偏差的來源,它們應該作為研究的局限性來討論。
未測混雜定義為與研究數據中未包含的變量相關的混雜,導致殘留混雜偏倚[67].雖然它是所有觀察性研究的潛在偏見來源,但在使用常規收集的數據的研究中尤其突出。分析可能需要一些在規劃數據庫或收集數據時沒有考慮到的變量。人們提出了各種方法來解決這種潛在的偏見來源[68- - - - - -71,包括傾向得分。然而,傾向評分分析,就像標準回歸分析和匹配,隻能保證研究參與者在數據中可用的變量上的平衡。一種特殊的不可測混雜是指指混雜;當使用常規收集的數據檢查(藥物)治療的有效性和安全性時,這通常是一個問題。因此,接受(藥物)治療的患者的預後可能比未接受(藥物)治療的患者更好或更差,但數據中可能無法提供有關預後和/或基礎疾病嚴重程度的信息[72].這些問題應該由作者討論,並且(如果可能的話)應該報告用於考慮這些問題的方法。
缺失數據對於所有的觀察研究都是有問題的,在STROBE解釋性文章的第6欄中已經討論過[10].對於常規收集的數據來說,數據缺失是一個特別的問題,因為研究人員無法控製數據收集[73].如果用於定義研究隊列的變量中缺少值,或者缺少阻止記錄鏈接的標識符,特別是如果缺少的數據是非隨機發生的,則缺失數據可能導致選擇偏倚。缺少變量也會帶來類似的挑戰。作者應該描述被懷疑導致不可測混雜的缺失變量,這些變量缺失的原因,這可能如何影響研究結果,以及用於調整缺失變量的方法。例如,吸煙狀況對克羅恩病的嚴重程度有很大影響,並與該病的預後有關。然而,吸煙狀況很少包括在衛生行政數據中。在一項評估社會經濟地位和克羅恩病預後之間關係的研究中,吸煙狀況被討論為一種潛在的不可測量的混雜因素[74].通常情況下,隻有在使用常規健康數據的研究開始之後,才會發現缺失的數據/缺失的變量,這使得研究人員有必要偏離最初的研究方案。無論偏離議定書的原因是什麼,都應報告偏離的詳細情況。應該討論產生偏差的原因以及對研究和結論的影響。
另一個重要的潛在限製是編碼實踐或資格標準的變化,這是由數據庫總體、研究總體或兩者隨時間的變化而引起的。數據庫總體的定義可能在一些情況下發生變化,例如,如果登記實踐停止與數據庫的協作,更改計算機軟件,或更改數據庫登記的更改標準,例如注冊表。如果由於就業、居住狀況或醫療保健提供者的變化,個人的資格隨著時間的推移不是恒定的,則行政數據源(如保險數據庫)中的研究人口可能會發生變化。記錄編碼方式的改變(例如,如上所述的上編碼或編碼係統的改變)可能會改變研究人群[63,75,76].當討論局限性時,作者應該解釋在分析中如何處理改變的資格,以便讀者可以評估潛在的偏見。如STROBE所述,討論應包括任何潛在偏差的方向和程度,以及為解決這種偏差所采取的努力。
其他信息
記錄項目22.1:作者應提供如何獲取任何補充信息的信息,如研究方案、原始數據或編程代碼。
解釋。
我們堅決支持傳播關於研究方法和結果的詳細信息。如果可能,我們鼓勵提前或同時發布研究方案、原始數據結果,以及(如果適用)編程代碼。這些信息對同行審稿人和讀者在評估研究結果的有效性時是有用的。研究人員有許多機會公開發表這類數據。這包括在線期刊補充材料、個人網站、機構網站、基於科學的社交媒體網站(例如ResearchGate.net和Academia.edu)、數據倉庫(例如Dryad或Figshare)或政府開放數據網站[79].我們認識到,一些研究組織、公司、機構或法律可能禁止或限製此類信息的免費獲取。雖然關於這些知識產權的所有權和使用的討論不在RECORD指南的範圍內,但發布這些數據應該始終在研究人員所在機構環境的法律和倫理指南的範圍內進行,並在期刊編輯的指導下進行。這些信息也將是有用的其他研究人員誰可能希望訪問這些數據複製,再現,或擴大在手稿中描述的研究。無論可用的補充信息的格式或範圍如何,我們建議在稿件中明確說明這些信息的位置。
討論
RECORD指南針對的是使用常規收集的健康數據進行的觀察性研究,是對STROBE指南的補充,而不是取代。RECORD的創建是為作者、期刊編輯、同行審稿人和其他利益攸beplay体育官网官方登录關方提供指南,以鼓勵使用常規收集的健康數據進行的研究報告的透明度和完整性。該清單供使用此類數據的任何研究人員使用,我們鼓勵向所有感興趣的各方廣泛傳播。我們預計,期刊對RECORD的認可和實施將提高使用常規收集的健康數據的研究報告的透明度。
限製
STROBE和RECORD都僅用於觀察性研究。然而,常規收集的健康數據有時被用於與其他研究設計一起進行的研究,如用於衛生係統評估的集群隨機試驗。此外,隨機試驗數據與行政數據的關聯可用於結果的長期隨訪,相關研究不被認為是觀察性的。隨著該領域的發展,我們希望將RECORD擴展到使用類似嚴格方法的其他研究設計。
雖然RECORD是我們為反映利益攸關方的興趣和優先事項所作的最佳努力,但我們認識到,使用常規收集的衛生數據進行研究的方法正在迅速變化,用於此類研究的數據類型正在擴大。例如,移動健康應用程序(mHealth apps)正廣泛應用於智能手機和可穿戴技術。雖然目前使用這些數據源進行的研究有限,但我們預計在不久的將來,這些數據的使用將迅速增長,並將創建新的方法來管理這些資源。此外,工作委員會決定重點關注衛生數據,而不是用於開展與衛生有關的研究的所有數據源(例如環境數據、財務數據等)。因此,RECORD清單可能沒有反映未來將變得重要的主題,在某些時候可能需要修改。
為使利益攸關方廣泛參與這些準則的製定作出了廣泛的努力。我們通過公開電話和利用各種渠道定向邀請的方式招募利益相關者[16].然而,利益攸關方代表主要來自利用定期收集的衛生數據進行研究的區域,隻有少數來自發展中國家和非英語國家的代表。盡管如此,我們相信利益相關者群體是當前研究人員和生成知識的用戶群體的代表。雖然大量的投入是通過調查和利益攸關方群體的反饋獲得的,但可行性決定了聲明是由一個較小的工作委員會起草的,該委員會由19名成員親自會麵,如文獻先前所建議的[17].未來,技術和社交媒體可能使更大的群體更積極地參與工作委員會會議。
結論
RECORD聲明將STROBE標準擴展到使用常規收集的健康數據進行的觀察性研究。在研究和出版界的投入下,我們以清單的形式製定了報告指南,並附上了這份解釋性文件。報告指南已被證明可以改進研究報告,從而使研究的消費者意識到結論的優勢、局限性和準確性[12,82- - - - - -84].雖然我們預計RECORD將隨著該領域研究方法的發展而改變,但這些指南將有助於在未來幾年促進充分的研究報告。通過作者、期刊編輯和同行審稿人的實施,我們預計RECORD將導致使用常規收集的健康數據進行的研究報告的透明度、可重複性和完整性。
致謝
這項工作得到了安大略東部兒童醫院研究倫理委員會的批準。作者感謝參與調查的利益相關者為清單中主題的優先次序所作的貢獻(S1表).我們也感謝STROBE倡議小組的成員,他們指導和支持了RECORD的創建。作者感謝RECORD研究協調員Pauline Quach和Danielle Birman的貢獻,以及網站設計師和recorstatement.org的管理員Andrew Perlmutar。作者也感謝所有利益攸關方為製定這些準則所作的貢獻。
記錄工作委員會成員:Douglas Altman(牛津大學醫學統計中心)、Nicholas de Klerk(西澳大利亞大學)、Lars G. Hemkens(巴塞爾大學醫院)、David Henry(多倫多大學和臨床評價科學研究所)、Jean-Marie Januel(洛桑大學)、Marie-Annick Le Pogam(洛桑大學醫院社會和預防醫學研究所)、Douglas Manuel(渥太華大學渥太華醫院研究所)、克裏斯汀•帕特裏克(編輯器,加拿大醫學協會雜誌[CMAJ]), Pablo Perel(倫敦衛生和熱帶醫學學院),Patrick S. Romano(加州大學戴維斯分校,衛生服務研究聯合主編),Peter Tugwell(渥太華大學,主編,臨床流行病學雜誌),瓊·沃倫(美國國立衛生研究院/國家癌症研究所),維姆·韋伯(歐洲編輯,BMJ)和瑪格麗特·溫克爾(前高級研究編輯,《公共科學圖書館·醫學》雜誌上;現任世界醫學編輯協會秘書)。
作者的貢獻
撰寫初稿:EIB SML。對稿件的撰寫有貢獻的有:EIB LS AG KH DM IP HTS EvE SML RECORD Working Committee成員。同意手稿的結果和結論:EIB LS AG KH DM IP HTS EvE SML成員的記錄工作委員會。
參考文獻
- 1.Spasoff RA。衛生政策的流行病學方法。紐約:牛津大學出版社;1999.
- 2.Morrato EH, Elias M, Gericke CA.使用基於人口的常規數據進行循證衛生政策決策:來自澳大利亞、英國和美國製定和評估國家衛生政策的三個例子的教訓。公共衛生雜誌(英國牛津)。2007; 29(4): 463 - 71。
- 3.De Coster C, Quan H, Finlayson A, Gao M, Halfon P, Humphries KH,等。利用ICD-9-CM和ICD-10行政數據確定方法研究的優先事項:來自一個國際聯盟的報告。BMC Health service Res. 2006;6:77。pmid: 16776836
- 4.赫姆肯斯·LG,本奇摩爾·EI,蘭根·SM,布裏埃爾·M,卡森達·B,詹尼埃爾·JM,等,編輯。使用常規收集的健康數據的研究報告:係統文獻分析(口頭摘要報告)。REWARD /赤道會議2015;2015年9月28 - 30;英國愛丁堡。
- 5.Benchimol EI, Manuel DG, To T, Griffiths AM, Rabeneck L, Guttmann A.用於評估衛生行政數據驗證研究質量的報告指南的開發和使用。臨床流行病學雜誌。2011;64(8):821-9。pmid: 21194889
- 6.Herrett E, Thomas SL, Schoonen WM, Smeeth L, Hall AJ。全科醫學研究數據庫中診斷的有效性和有效性:係統回顧。英國臨床藥理學雜誌。2010;學報》第4 - 14(1):69。pmid: 20078607
- 7.羅思曼[KJ,格陵蘭S,鞭什TL.現代流行病學,第三版。費城:Lippincott Williams & Wilkins;2008.
- 8.Plint AC, Moher D, Morrison A, Schulz K, Altman DG, Hill C,等。CONSORT檢查表是否提高了隨機對照試驗報告的質量?係統回顧。澳大利亞醫學雜誌。2006;185(5):263-7。pmid: 16948622
- 9.提高衛生研究的質量和透明度(赤道)網絡圖書館2015[引自2015年3月7日]。http://www.equator-network.org/library/.
- 10.Vandenbroucke JP, von Elm E, Altman DG, Gotzsche PC, Mulrow CD, Pocock SJ,等。加強流行病學觀察性研究報告(STROBE):解釋和闡述。《公共科學圖書館·醫學》雜誌。2007;4 (10):e297。pmid: 17941715
- 11.von Elm E, Altman DG, Egger M, Pocock SJ, Gotzsche PC, Vandenbroucke JP加強流行病學觀察性研究報告(STROBE)聲明:報告觀察性研究的指南。《公共科學圖書館·醫學》雜誌。2007;4 (10):e296。pmid: 17941714
- 12.Sorensen AA, Wojahn RD, Manske MC, Calfee RP。使用加強流行病學觀察性研究報告(STROBE)聲明來評估手外科觀察性試驗的報告。手外科雜誌。2013; 38 (8): 1584 - 9. - e2。pmid: 23845586
- 13.Cobo E, Cortes J, Ribera JM, Cardellach F, Selva-O'Callaghan A, Kostov B,等。在同行評審期間使用報告指南對提交給生物醫學期刊的最終稿件質量的影響:掩蓋隨機試驗。BMJ。2011; 343: d6783。pmid: 22108262
- 14.Benchimol EI, Langan S, Guttmann A.呼籲記錄:使用常規收集的健康數據的研究需要完整的報告。臨床流行病學雜誌,2013;66(7):703-5。pmid: 23186992
- 15.Langan SM, Benchimol EI, Guttmann A, Moher D, Petersen I, Smeeth L,等。澄清記錄:為使用常規收集的觀察性數據進行的研究製定報告指南。中國論文。2013;5:29-31。pmid: 23413321
- 16.Nicholls SG, Quach P, von Elm E, Guttmann A, Moher D, Petersen I,等。使用觀察性常規收集的健康數據(RECORD)聲明進行的研究報告:達成共識和製定報告指南的方法。《公共科學圖書館•綜合》。2015;10 (5):e0125620。pmid: 25965407
- 17.Moher D, Schulz KF, Simera I, Altman DG。為製定健康研究報告準則的人員提供的指導。《公共科學圖書館·醫學》雜誌。2010;7 (2):e1000217。pmid: 20169112
- 18.Glasziou P, Altman DG, Bossuyt P, Boutron I, Clarke M, Julious S,等。減少生物醫學研究報告的不完整或不可用造成的浪費。柳葉刀》。2014;383(9913):267 - 76。pmid: 24411647
- 19.Blotiere PO, Weill A, Ricordeau P,真主安拉F, Allemand H. 2010年結腸鏡檢查後穿孔和出血:一項基於法國綜合健康保險數據(SNIIRAM)的研究。中華醫學會肝病雜誌。2014;38(1):112-7。pmid: 24268997
- 20.Siregar S, Pouw ME, Moons KG, Versteegh MI, Bots ML, van der Graaf Y,等。荷蘭醫院標準化死亡率(HSMR)方法與心髒手術:使用醫院管理數據與臨床數據庫在全國隊列中進行基準測試。心。2014;100(9):702 - 10。pmid: 24334377
- 21.Price SD, Holman CD, Sanfilippo FM, Emery JD。病例-時間-控製設計在藥物警戒應用中的應用:探索高風險藥物和西澳老年人的計劃外住院。中國藥物流行病學雜誌2013;22(11):1159-70。pmid: 23797984
- 22.Gross CP, Andersen MS, Krumholz HM, McAvay GJ, Proctor D, Tinetti ME。老年結腸癌患者醫療保險篩查報銷與診斷階段的關係。《美國醫學協會雜誌》上。2006、296(23):2815 - 22所示。pmid: 17179458
- 23.Vandenbroucke JP。觀察研究,隨機試驗,以及兩種醫學科學觀點。《公共科學圖書館·醫學》雜誌。2008;5 (3):e67。pmid: 18336067
- 24.數據疏通、偏見或混淆。BMJ。2002, 325(7378): 1437 - 8。pmid: 12493654
- 25.醫學信息學展望。利用電子病曆進行臨床研究。方法中華醫學雜誌2009;48(1):38-44。pmid: 19151882
- 26.Benchimol EI, Manuel DG, Guttmann A, Nguyen GC, Mojaverian N, Quach P,等。加拿大安大略省炎症性腸病的年齡統計學變化:一項基於人群的流行病學趨勢隊列研究炎症腸病雜誌2014;20(10):1761-9。pmid: 25159453
- 27.Ducharme R, Benchimol EI, Deeks SL, Hawken S, Fergusson DA, Wilson K.加拿大安大略省兒童腸套疊診斷代碼的驗證和發生率的量化:一項基於人群的研究。J Pediatr。2013;163 (4):1073 - 9. - e3。pmid: 23809052
- 28.Herrett E, Shah AD, Boggon R, Denaxas S, Smeeth L, van Staa T,等。在初級保健、醫院護理、疾病登記和全國死亡記錄中記錄急性心肌梗死事件的完整性和診斷有效性:隊列研究BMJ。2013; 346: f2350。pmid: 23692896
- 29.van Herk-Sukel MP, van de Poll-Franse LV, Lemmens VE, Vreugdenhil G, Pruijt JF, Coebergh JW,等。癌症患者藥物療效研究的新機遇:埃因霍溫癌症注冊和PHARMO記錄鏈接係統的鏈接。歐洲癌症雜誌(牛津,英格蘭:1990)。46 2010;(2): 395 - 404。
- 30.Fosbol EL, Granger CB, Peterson ED, Lin L, Lytle BL, Shofer FS,等。st段抬高心肌梗死護理中的院前係統延遲:急診醫學服務和醫院注冊數據的一種新的聯係。中國科學(d輯:自然科學版)2013;pmid: 23453105
- 31.Manuel DG, Rosella LC, Stukel TA。在使用電子健康記錄的研究中準確識別疾病的重要性。BMJ。2010; 341: c4226。pmid: 20724404
- 32.與大流行性流感疫苗接種有關的嗜睡症(歐洲多國流行病學調查)斯德哥爾摩:ECDC。斯德哥爾摩:歐洲疾病預防和控製中心。, 2012年9月。ISBN 978-92-9193-388-4。https://doi.org/10.2900/63210
- 33.王旭,王曉東,王曉東。藥物流行病學研究中健康改善網絡(THIN)數據庫的有效性研究。藥物流行病學雜誌2007;16(4):393-401。pmid: 17066486
- 34.蘇倫森,王曉燕,王曉燕,等。流行病學研究中二級數據源的評價框架。國際流行病學雜誌。1996; 25(2): 435 - 42。pmid: 9119571
- 35.賈男爵,陸堯G,巴雷特J,麥克萊恩D,費希爾ES。醫療保險索賠數據的內部驗證。流行病學。1994;5(5):541 - 4。pmid: 7986870
- 36.Marston L, Carpenter JR, Walters KR, Morris RW, Nazareth I, White IR等。吸煙者,戒煙者還是不吸煙者?英國初級保健中常規記錄吸煙狀況的有效性:一項橫斷麵研究。beplay体育官方手机版BMJ開放。4 (4): e004958。2014;pmid: 24760355
- 37.Hardelid P, Dattani N, Gilbert R.估計英格蘭、蘇格蘭和威爾士死亡兒童中慢性疾病的患病率:一項數據關聯隊列研究。beplay体育官方手机版BMJ開放。2014; 4 (8): e005331。pmid: 25085264
- 38.Murray J, Bottle A, Sharland M, Modi N, Aylin P, Majeed A,等。英國RSV細支氣管炎住院的危險因素:一項基於人群的出生隊列研究《公共科學圖書館•綜合》。2014;9 (2):e89186。pmid: 24586581
- 39.Berry JG, M廳,DE廳,Kuo DZ, Cohen E, Agrawal R,等。28家兒童醫院的住院患者增長和資源使用:一項縱向、多機構研究JAMA兒科。2013年,167(2):170 - 7。pmid: 23266509
- 40.Shahian DM, Wolf RE, Iezzoni LI, Kirle L, Normand SL.全醫院死亡率測量的變動性。中華醫學雜誌2010;363(26):2530-9。pmid: 21175315
- 41.斯普林ate DA, Kontopantelis E, Ashcroft DM, Olier I, Parisi R, Chamapiwa E,等。ClinicalCodes:一個在線臨床代碼存儲庫,用於使用電子醫療記錄提高研究的有效性和可重複性。《公共科學圖書館•綜合》。2014;9 (6):e99825。pmid: 24941260
- 42.Dommett RM, Redaniel MT, Stevens MC, Hamilton W, Martin RM。兒童癌症在初級保健中的特征:一項基於人群的嵌套病例對照研究。中華癌症雜誌2012;106(5):982-7。pmid: 22240793
- 43.Tsang C, Bottle A, Majeed A, Aylin P.英國初級保健記錄的不良事件:使用全科醫學研究數據庫的觀察性研究。中華實用醫學雜誌2013;63(613):e534-42。pmid: 23972194
- 44.Harron K, Goldstein H, Wade A, Muller-Pebody B, Parslow R, Gilbert R.國家電子醫療數據的鏈接、評估和分析:在兒科重症監護中提供強化血流感染監測的應用。《公共科學圖書館•綜合》。2013;8 (12):e85278。pmid: 24376874
- 45.Adams MM, Wilson HG, Casto DL, Berg CJ, McDermott JM, Gaudino JA,等。通過聯係生命記錄來構建生殖曆史。中華流行病學雜誌1997;145(4):339-48。pmid: 9054238
- 46.Ford JB, Roberts CL, Taylor LK。關聯出生記錄和出院數據中不匹配的產婦和嬰兒記錄的特征。兒科圍產期流行病學。2006;20(4):329-37。pmid: 16879505
- 47.韋斯科普夫,吳文昌。電子健康記錄數據質量評估的方法和維度:允許重複用於臨床研究。美國醫學信息協會雜誌:JAMIA。2013; 20(1): 144 - 51。pmid: 22733976
- 48.Sandall J, Murrells T, Dodwell M, Gibson R, Bewley S, Coxon K,等。產科勞動力的有效利用和對產科護理安全和質量的影響:一項基於人口的橫斷麵研究。《衛生服務交付決議》2014;2(38)。
- 49.韋爾奇C,彼得森I,沃爾特斯K,莫裏斯RW,拿撒勒I,卡拉紮基E,等。從初級保健數據庫的縱向數據中去除人群和個體水平異常值的兩階段方法。藥物流行病學雜誌2012;21(7):725-32。pmid: 22052713
- 50.Van den Broeck J, Cunningham SA, Eeckels R, Herbst K.數據清理:檢測、診斷和編輯數據異常。《公共科學圖書館·醫學》雜誌。2005;2 (10):e267。pmid: 16138788
- 51.Bohensky MA, Jolley D, Sundararajan V, Evans S, Pilcher DV, Scott I,等。數據鏈接:一個具有潛在問題的強大研究工具。BMC Health Serv Res. 2010;10:346。pmid: 21176171
- 52.Harron K, Wade A, Muller-Pebody B, Goldstein H, Gilbert R.打開記錄鏈接的黑盒子。流行病學雜誌,2012;66(12):1198。pmid: 22705654
- 53.Lariscy JT。在相關死亡率研究中,西班牙裔種族和年齡的差異記錄聯係:對流行病學悖論的啟示。中國老年醫學雜誌,2011;23(8):1263-84。pmid: 21934120
- 54.Dinan MA, Curtis LH, Carpenter WR, Biddle AK, Abernethy AP, Patz EF Jr.等。1998-2007年非小細胞肺癌醫療保險受益人PET使用的差異。放射學。2013;267(3):807 - 17所示。pmid: 23418003
- 55.Horsfall L, Walters K, Petersen I.確定初級保健研究數據庫中可接受的計算機使用周期。中國藥物流行病學雜誌2013;22(1):64-9。pmid: 23124958
- 56.Gerber DE, Laccetti AL, Xuan L, Halm EA, Pruitt SL.既往癌症對肺癌臨床試驗資格的影響。中華腫瘤雜誌2014;106(11)。
- 57.Carrara G, Scire CA, Zambon A, Cimmino MA, Cerra C, Caprioli M,等。使用行政健康數據庫識別類風濕關節炎的新分類算法的驗證研究:病例對照和隊列診斷準確性研究。意大利風濕病學會風濕病研究記錄鏈接的結果。beplay体育官方手机版BMJ開放。5 (1): e006029。2015;pmid: 25631308
- 58.Rait G, Walters K, Griffin M, Buszewicz M, Petersen I, Nazareth I.初級保健中記錄的抑鬱症發病率的近期趨勢。中華精神病學雜誌2009;195(6):520-4。pmid: 19949202
- 59.Wijlaars LP, Nazareth I, Petersen I.兒童和青少年抑鬱和抗抑鬱藥物處方的趨勢:健康改善網絡(THIN)的一項隊列研究。《公共科學圖書館•綜合》。2012;7 (3):e33181。pmid: 22427983
- 60.Jeon CY, Pandol SJ, Wu B, Cook-Wiens G, Gottlieb RA, Merz NB,等。胰腺癌患者癌症診斷後使用他汀類藥物與生存期的關係:一項SEER-Medicare分析。《公共科學圖書館•綜合》。2015;10 (4):e0121783。pmid: 25830309
- 61.普魯伊特·Z,普魯伊特·e,對兒童非生命危險傷害的緊急入院進行編碼。美國管理醫療雜誌。2013; 19(11): 917 - 24。pmid: 24511988
- 62.McLintock K, Russell AM, Alderson SL, West R, House A, Westerman K,等。經濟激勵對糖尿病和冠心病患者抑鬱症病例發現的影響:間斷時間序列分析。beplay体育官方手机版BMJ開放。2014; 4 (8): e005178。pmid: 25142262
- 63.衝擊CS。醫療保險b部分下的CPT費用差異和訪問編碼。2011; 20(7): 831 - 41。pmid: 20681033
- 64.Walters K, Rait G, Griffin M, Buszewicz M, Nazareth I.初級保健中焦慮診斷和症狀發生率的近期趨勢。《公共科學圖書館•綜合》。2012;7 (8):e41670。pmid: 22870242
- 65.Nilson F, Bonander C, Andersson R.《國際疾病分類》第九次修訂至第十次修訂對瑞典傷害發病率外因登記的影響。傷害預防:國際兒童和青少年傷害預防學會雜誌2015;21(3):189-94。pmid: 25344579
- 66.賈蓋JS,史密斯GS,施密德JE,韋德TJ。美國腸胃炎相關死亡率的趨勢,1985年倒問號2005:ICD-9和ICD-10編碼的變化。BMC雜誌。2014;14(1):211。pmid: 25492520
- 67.歐洲藥物流行病學和藥物警戒中心網絡藥物流行病學方法學標準指南,4.2.2.5。不可估量的混雜[3月10日]。英國倫敦:歐洲藥品管理局;2015(2015年更新;引用2015年5月17日]。http://www.encepp.eu/standards_and_guidances/methodologicalGuide4_2_2_5.shtml.
- 68.Toh S, Garcia Rodriguez LA, Hernan MA。基於半自動化高維傾向評分算法的混雜校正:在電子病曆中的應用。藥物流行病學雜誌2011;20(8):849-57。pmid: 21717528
- 69.Stukel TA, Fisher ES, Wennberg DE, Alter DA, Gottlieb DJ, Vermeulen MJ。存在治療選擇偏倚的觀察性研究分析:采用傾向評分和工具變量方法對有創心髒治療對AMI生存率的影響。《美國醫學協會雜誌》上。2007;297(3):278 - 85。pmid: 17227979
- 70.奧斯丁的電腦。在觀察性研究中減少混雜影響的傾向評分方法介紹。多元行為研究。2011年,46(3):399 - 424。pmid: 21818162
- 71.斯特恩JA,懷特IR,卡林JB,斯普拉特M,羅伊斯頓P,肯沃德MG,等。流行病學和臨床研究中缺失數據的多重歸責:潛力和缺陷。BMJ。2009; 338: b2393。pmid: 19564179
- 72.Freemantle N, Marston L, Walters K, Wood J, Reynolds MR, Petersen I.從真實世界的數據中推斷治療效果:傾向評分,指征混淆,以及觀察研究中粗心者的其他危險。BMJ。2013; 347: f6409。pmid: 24217206
- 73.Marston L, Carpenter JR, Walters KR, Morris RW, Nazareth I, Petersen I.大型全科臨床數據庫中缺失數據的多重歸因問題。藥物流行病學雜誌2010;19(6):618-26。pmid: 20306452
- 74.王曉燕,李曉燕,王曉燕。兒童炎症性腸病的臨床研究進展。J Pediatr。2011;158 (6):960 - 7. - e1 - 4。pmid: 21227449
- 75.Nassar N, Dixon G, Bourke J, Bower C, Glasson E, de Klerk N,等。幼兒自閉症譜係障礙:診斷方法變化的影響。國際流行病學雜誌。38 2009;(5): 1245 - 54。pmid: 19737795
- 76.Tan GH, bhu - pathy N, Taib NA, See MH, Jamaris S, Yip CH. Will Rogers現象對乳腺癌分期有影響嗎?癌症論文。2015;39(1):115 - 7。pmid: 25475062
- 77.Taljaard M, Tuna M, Bennett C, Perez R, Rosella L, Tu JV,等。心血管疾病人群風險工具(CVDPoRT):在社區環境中評估心血管疾病風險的預測算法。一項協議。beplay体育官方手机版BMJ開放。2014; 4 (10): e006701。pmid: 25341454
- 78.Guttmann A, Schull MJ, Vermeulen MJ, Stukel TA。等待時間、短期死亡率和從急診科出院後住院之間的關聯:來自加拿大安大略省的基於人群的隊列研究BMJ。2011; 342: d2983。pmid: 21632665
- 79.王曉燕,王曉燕,王曉燕。開放數據訪問政策與策略的研究進展。加拿大蒙特利爾:Science-Metrix公司,2013年8月報告No。
- 80.富勒T,皮爾森M,彼得斯J,安德森R.什麼影響作者和編輯使用報告指南?調查結果來自在線調查和定性訪談。《公共科學圖書館•綜合》。2015;10 (4):e0121585。pmid: 25875918
- 81.Turner L, Shamseer L, Altman DG, Weeks L, Peters J, Kober T,等。報告試驗的統一標準(CONSORT)和在醫學期刊上發表的隨機對照試驗(rct)報告的完整性。Cochrane Database Syst Rev. 2012;11:Mr000030。
- 82.Armstrong R, Waters E, Moore L, Riggs E, Cuervo LG, Lumbiganon P,等。改進公共衛生幹預研究報告:推進趨勢和CONSORT。公共衛生雜誌(英國牛津)。2008; 30(1): 103 - 9。
- 83.Moher D, Cook DJ, Eastwood S, Olkin I, Rennie D, Stroup DF。提高隨機對照試驗meta分析報告的質量:QUOROM聲明。元分析報告的質量。柳葉刀》。1999;354(9193):1896 - 900。pmid: 10584742
- 84.Prady SL, Richmond SJ, Morton VM, Macpherson H.對STRICTA和CONSORT建議對針灸試驗報告質量影響的係統評估。《公共科學圖書館•綜合》。2008;3 (2):e1577。pmid: 18270568