條文本

摘要
目標本研究的目的是對COVID-19潛伏期的估計進行快速係統回顧和薈萃分析。
設計觀察性研究的快速係統回顧和薈萃分析。
設置新冠肺炎潛伏期的國際研究。
參與者搜索在PubMed、穀歌Scholar、Embase、Cochrane圖書館以及預印本服務器MedRxiv和BioRxiv上進行。如果報告的分布參數和ci符合數據,或有足夠的信息便於計算這些值,則選擇這些研究進行meta分析。在初步合格篩選後,選取了24項研究進行初步評審,其中9項入選進行meta分析。最終估計來自8項研究的薈萃分析。
主要結果測量潛伏期的對數正態分布參數。
結果潛伏期分布可以用對數正態分布建模,其中mu和sigma參數(95% CI)分別為1.63 (95% CI 1.51至1.75)和0.50 (95% CI 0.46至0.55)。相應的平均(95% CI)為5.8天(95% CI 5.0至6.7天)。應該注意的是,不確定性在分布尾部增加:彙集參數估計(95% CI)得出的潛伏期中位數為5.1天(95% CI 4.5至5.8天),而第95百分位為11.7天(95% CI 9.7至14.2天)。
結論采用哪些參數值的選擇將取決於如何使用信息、相關風險和所作決定的可感知後果。一旦獲得進一步的相關資料,將需要重新審議這些建議。因此,我們提出了一個R Shiny應用程序,它可以在新的數據可用時方便地更新這些估算。
- 流行病學
- 公共衛生
這是一篇開放獲取的文章,按照創作共用署名非商業性(CC BY-NC 4.0)許可發布,該許可允許其他人以非商業性的方式發布、混編、改編、構建本作品,並以不同的條款授權他們的衍生作品,前提是原創作品被正確引用,給予適當的榮譽,任何更改都被注明,且使用是非商業性的。看到的:http://creativecommons.org/licenses/by-nc/4.0/.
來自Altmetric.com的統計
本研究的優勢和局限性
本研究提供了潛伏期分布的綜合估計,可用於後續的模擬研究或為決策提供信息。
幾項研究使用了公開的數據,因此有可能一些數據可能被用於多個研究。
在獲得後續數據後,將需要重新評估這一估計數。因此,我們提出了一個R Shiny應用程序,允許用新的估計更新元分析。
簡介
對潛伏期的可靠估計對控製人類傳染病的決策很重要。有關潛伏期的知識可直接用於指導有關傳染病控製的決策。例如,最長潛伏期可用於告知隔離的持續時間,或告知高接觸風險人群的積極監測期。對潛伏期持續時間的估計,加上對潛伏期、連續間隔或產生時間的估計,可能有助於推斷出症狀前感染期的持續時間,這對了解感染的傳播和控製機會都很重要。1最後,在大流行期間做出決策往往依賴於預測事件,例如從數學模型得出的每日新感染人數。這種模型取決於與特定傳染病傳播有關的關鍵輸入參數。這類模型的輸入參數必須盡可能穩健,這一點很重要。考慮到一些模型將數據與許多參數擬合,其中隻有一些參數是特別感興趣的,但所有參數都是相互依賴的,輸出估計可以與穩健性估計進行比較,作為模型驗證的一部分。
早期的工作表明,對於呼吸道感染的模型,有關潛伏期的陳述往往缺乏參考、不一致或基於有限的數據。2迄今為止,許多COVID-19模型使用了來自單一研究的輸入值。使用哪種研究的決定可能因模型而異。最近,一項對COVID-19流行病學特征的係統綜述報告稱,估計潛伏期集中趨勢為4至6天。3.然而,據作者所知,目前還沒有研究試圖通過對現有數據的元分析來估計潛伏期。此外,重要的是要注意到,潛伏期預計在人群中因人而異。因此,了解種群內潛伏期(即分布)的變化是至關重要的。然而,集中趨勢的單一度量(即平均值或中位數)不能充分表示這種變化。4為了解決這一問題,研究經常對潛伏期數據進行數學分布。
我們假設,可以通過對迄今為止發表的數據進行薈萃分析,獲得潛伏期分布的綜合估計。因此,本研究的目的是對COVID-19潛伏期(定義為從接觸病毒到出現症狀的時間(以天為單位))的估計進行快速係統回顧和元分析。具體地說,我們的目標是找到一個適當分布的參數的集合估計,可以隨後用作建模研究的輸入,這可能有助於量化分布的關鍵百分位數周圍的不確定性,以幫助決策。
材料和方法
為了本研究的目的,我們遵循了流行病學指南中觀察性研究的meta分析。5結果定義為從接觸點(在本例中為感染)到出現臨床症狀的天數;所有觀察性研究均納入分析。最後,人群被確認為感染個體,暴露時間可以在一定程度上確定和精確。
患者和公眾的參與
讓病人或公眾參與我們研究的設計、實施、報告或傳播計劃是不合適的,也不可能的。
搜索方法,初步篩選和分類
采用以下搜索策略對2019年12月1日至2020年4月8日期間所有國家的文獻進行了調查。使用以下關鍵詞搜索電子數據庫PubMed、穀歌Scholar、Embase、Cochrane圖書館以及預印本服務器MedRxiv和BioRxiv上的出版物:“新型冠狀病毒”或“SARS-CoV-2”或“2019-nCoV”或“COVID-19”和“潛伏期”或“潛伏期”(在線補充表S1).除了國家和國際政府報告外,還監測了動態策劃的PubMed數據庫“LitCovid”。隻要有英文摘要,就不限製語言或出版地位。對有關文章的數據進行了評價,並考慮可能納入所有有關出版物。還檢索了這些出版物的參考書目以尋找其他資源。最初的搜索由三名調查人員進行(ÁC, KH, FB)。聯係研究報告的作者隻是為了澄清報告問題。
初步研究評價和薈萃分析的選擇
搜索結果分兩個階段進行篩選。首先,對標題和摘要進行篩選,隻保留相關文章。如果研究涉及的是不反映總體人群的特定隊列的病例,就會被刪除。接下來,詳細閱讀文章,如果報告的分布參數和ci符合數據,或有足夠的信息便於計算這些值,就選擇研究進行元分析。具體來說,這包括報告的研究:每個參數的點估計和ci或SEs;帶ci的原始(非轉換)標度上的平均值和標準差;分布的平均值和一個或多個百分位(含ci);或兩個或兩個以上百分比的分布(包括ci)。如果研究描述了分布(如平均值、中位數、百分位數),但沒有報告該數字周圍的任何不確定性,則被排除在外。納入meta分析的研究的選擇由第一作者(CM)進行。
對入選研究的質量評估
一旦研究入圍,兩位作者(CM, SJM)獨立地對研究質量進行評估。據作者所知,目前還沒有可用的質量評估工具來評估報告傳染病潛伏期的研究。我們使用紐卡斯爾-渥太華量表來評估meta分析中非隨機化研究的質量6並根據潛伏期研究的重要質量和報告指標對其進行了修改。特別是,增加了用於評估定義曝光窗口的準確性和精確度的字段。與未暴露隊列相關的字段被刪除。最後,我們用字母分類係統代替了“星號”係統。修改後的比例尺為在線補充材料.在兩位作者對研究進行評價後,對結果進行比較,通過討論解決得分差異,直到達成共識。
數據提取
在初步評估中,很明顯,大多數研究符合對數正態分布的數據。早期的研究表明,這種分布適用於許多急性傳染病。2 7因此,本研究作為該分布參數的薈萃分析(彙集估計)進行。
當對數變換後的值與均值(mu)和方差(sigma)服從正態分布時,變量(X)具有對數正態分布2,即:
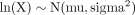
現有的方法用於將對數轉換和非轉換數據混合在一起的研究的元分析。8在本例中,我們選擇將數據轉換為可能的對數轉換尺度,並獲得對和的綜合估計。
計算各研究的分布參數
當每個參數(mu和sigma)的值都可以從研究中獲得,以及相應的ci /SEs時,將根據報告提取這些值。在其餘的研究中,在可能的情況下根據所提供的資料計算數值。
從報告原始尺度上對數正態分布的均值和標準差的研究中計算mu和sigma
原始對數正態分布的參數計算為:
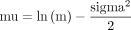
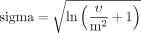
在哪裏v=方差(= SD2),米=原始(即非對數變換)標度上分布的均值。
類似地,通過將平均值或SD(來自原始刻度)的上下限替換到上麵的方程中,每次替換一個,同時保持另一個參數常數的值(作為該參數的點估計值),可以找到mu和sigma的上下限ci。
根據原始比例尺上報告平均值和百分位數的研究計算mu和sigma
當研究報告的結果是原始刻度上的平均值和第95百分位時,R中的“lognorm”包被用來計算mu和sigma以及相應的SEs或ci的原始值。9
和的方差計算
對於報告ci的研究,SE計算為(上界-下界)/(2×1.96)。最後,對於報告了相對於參考值的參數的研究,SE計算為:
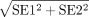
在SE1和SE2分別為參考類別和係數估計的SEs。
薈萃分析
隨機效應meta分析在RStudio V.1.2.5033中進行,10使用“metfor”包,11對數正態分布的和參數,使用“yi”(即點估計)和“sei”(即SE)參數指定點估計和SE。使用同樣的軟件包製作森林地塊。使用Egger 's檢驗和漏鬥圖獲得了偏倚的定量估計。異質性用I量化2通過對數據集進行亞組分析進行統計和調查。
根據mu和sigma的綜合估計值計算原始尺度上的SEM和SD
彙總估計的平均值和標準差被轉換為原始(即非對數轉換)比例尺如下:
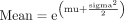

通過一次替換一個和的上界和下界,並重新計算平均數和標準差的後續數字,可以找到上下限ci。
使用R中的' ggplot2 '包繪製結果分布。12此外,那些不符合對數正態分布,但報告了擬合備選分布參數的研究的分布也與合並的對數正態分布一起繪製。
最後,我們創建了一個R Shiny應用程序,它可以隨著新數據的出現而更新元分析估計。
結果
在初步搜索和選擇有關論文並刪除重複後,有24份研究報告可供評價。
一項研究被刪除,因為隻有英文摘要,沒有足夠的細節來提取相關結果。15
有幾篇論文被刪除,因為它們沒有足夠的數據或方法說明以方便納入:
在入圍的研究中(n=11), 6個報告的對數正態分布最適合數據。26-31在其餘四份報告中,有一份報告說,已試行若幹份分發,但不清楚使用哪一份分發進行最後估計數。32然而,這些作者提供了原始數據,我們使用“rriskdistribution”包來擬合對數正態分布的參數。33其餘四項研究報告稱,威布爾分布或伽馬分布更符合數據。其中,兩項研究也給出了符合數據的對數正態分布的結果,34 35促進將其納入後續分析。其中一項研究35報告了兩種不同人群的潛伏期:旅行者和非旅行者。對各隊列的估計有顯著差異。作者認為,這種差異可能是由旅行者隊列中的多次暴露所致。因此,在我們的分析中,我們選擇隻使用報告的非旅行者隊列的估計。
最後兩項研究報告了威布爾36和分布37在這個階段從進一步的分析中刪除,但是,這些分布被繪製在最終分布上,以評估刪除這些估計的影響。最終研究的特征以及用於元分析的最終mu和sigma值顯示在表1.
質量評價(在線補充表S2)表明,很少有研究精確概述了研究中使用的暴露時間窗和症狀發作時間窗。幾項研究報告稱,他們對一小群特征良好的病例進行了分析。這可能隻包括短時間(1天)接觸和出現症狀窗口期的個人。然而,這在一些研究中並沒有明確報道。
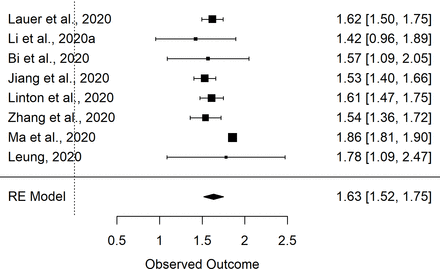
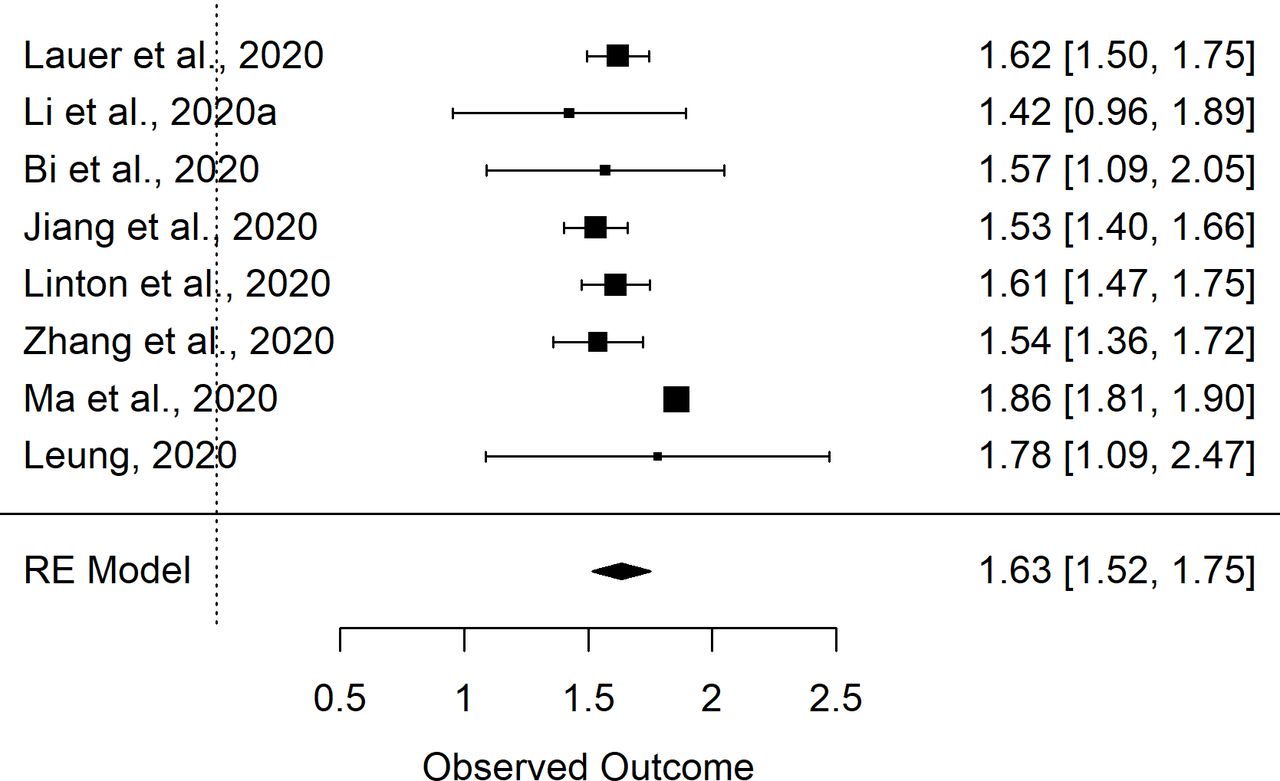
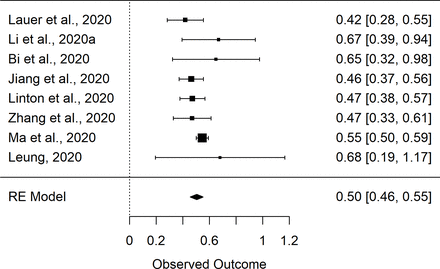
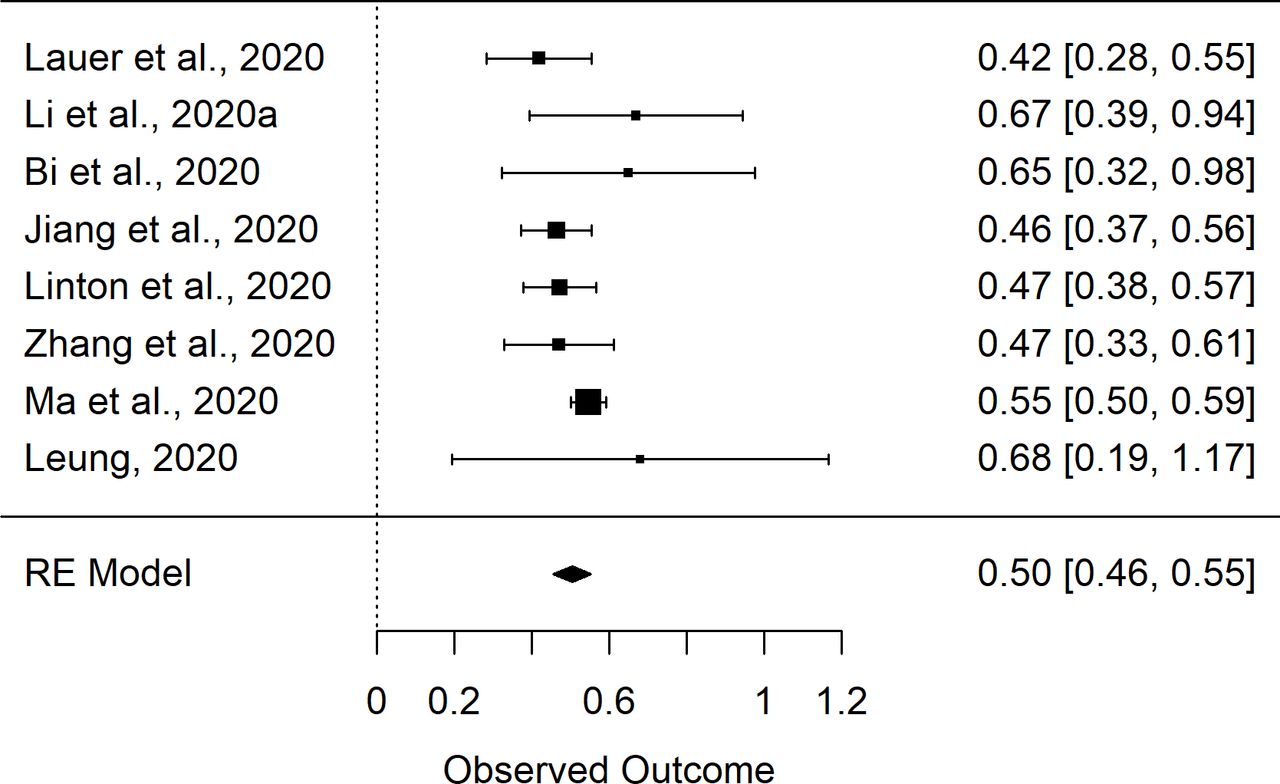
該數據集(即數據集1,n=8項研究)中mu的初始彙總估計為1.66 (1.55,1.76),sigma的彙總估計為0.48(0.42,0.54)。我的2mu和sigma分別為75%和56%。和sigma的Egger檢驗在統計學上不顯著;分別為P =0.31和P =0.20。然而,漏鬥圖的評價(在線補充圖S1和S2)表明分析中包含的其中一項研究可能存在偏見。30.對mu的meta分析結果的評價表明,兩項研究導致了該值分析的大部分異質性。特別是馬雲所報告的價值觀等30.和支持者等34高於其他研究的估計。進一步評估了兩項研究,以確定這些差異是否可能是由於方法的差異。的支持者等34該研究隨後被排除在外,因為暴露窗口的定義似乎有些不精確,可能會使這一估計偏高。相反,馬的研究報告等30.僅使用暴露窗口為3天或更短時間的患者,大多數患者持續時間為1天。對讚助者進行了重複的元分析等34研究被刪除(即數據集2,n=7項研究)。結果彙總估計為1.63(1.51,1.75)和0.50(0.46,0.55),而I2mu和sigma分別為75%和24%。圖1及2分別顯示來自數據集2 (n=8)的mu和sigma元分析的結果森林圖,即從其中提取參數的9項研究中減去Backer等34估計。
{kind=link}
{kind=link}
潛伏期對數正態分布參數的隨機效應(RE)元分析的森林圖。
{kind=link}
{kind=link}
森林圖的隨機效應(RE)元分析的sigma參數的對數正態分布。
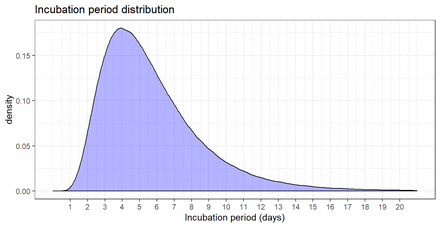
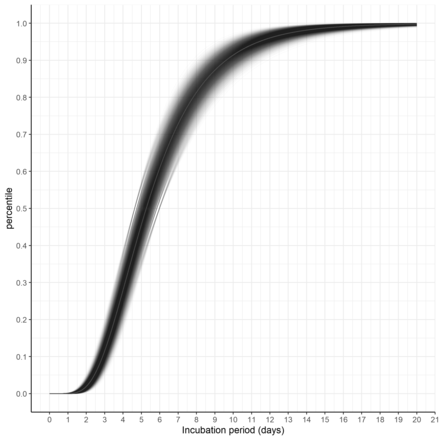
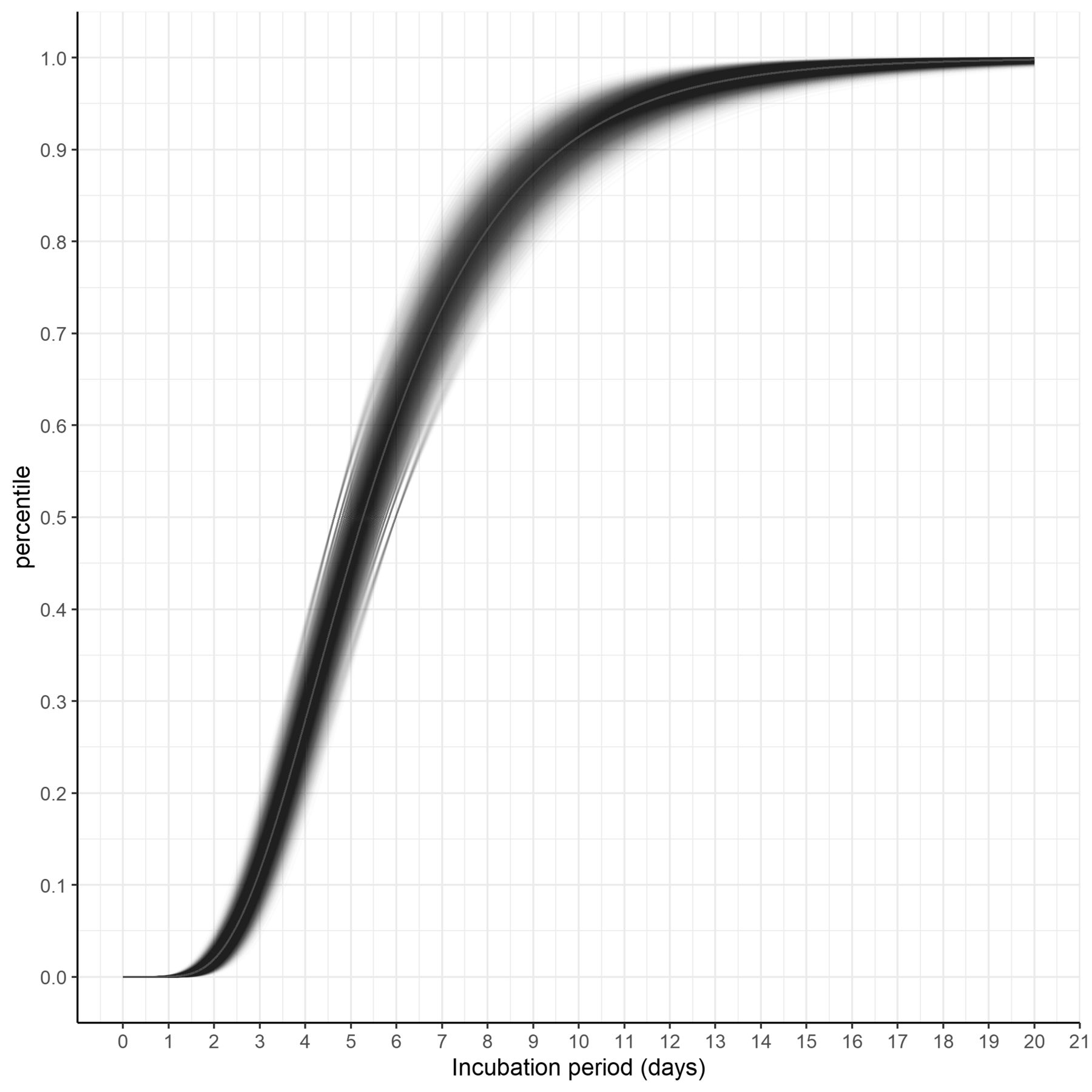
圖3顯示合並分布的結果密度圖。圖4顯示相同的累積密度函數圖(彙集分布)。在這個例子中,每一個估計值和σ值的95% ci分布的所有可能組合都繪製在同一個圖上。表2顯示了合並對數正態分布的百分位數和相應的ci。
{kind=link}
{kind=link}
報告潛伏期合並對數正態分布的概率密度函數,mu=1.63, sigma=0.50。
{kind=link}
{kind=link}
彙集對數正態分布的累積分布函數。和σ的95% ci之間的每一種可能的值組合都用單條黑線表示。
圖5顯示了彙集對數正態分布的累積密度函數圖以及原始研究的估計。最後,圖6顯示了合並對數正態分布的概率密度函數,並與兩項研究一起繪製,由於它們為數據擬合了替代分布,因此未能納入最終的薈萃分析。
{kind=link}
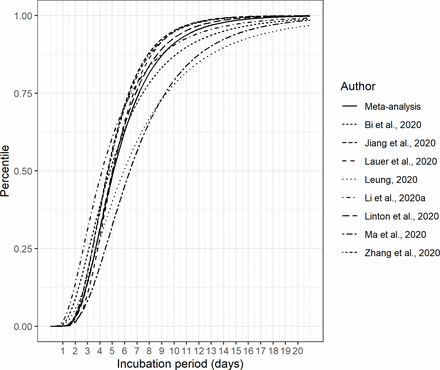
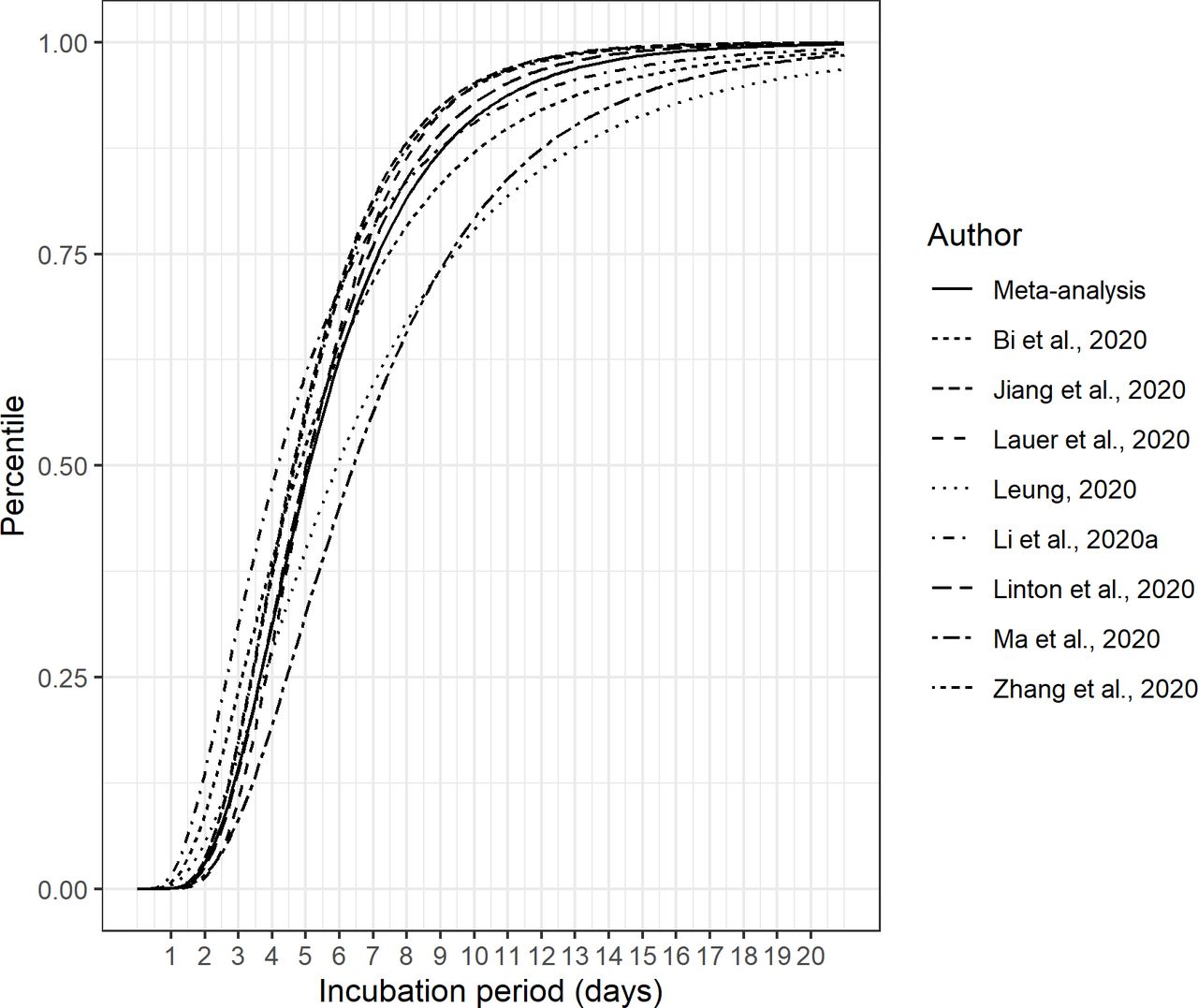{kind=link}
潛伏期與原始輸入研究的合並對數正態分布的累積分布函數。
{kind=link}
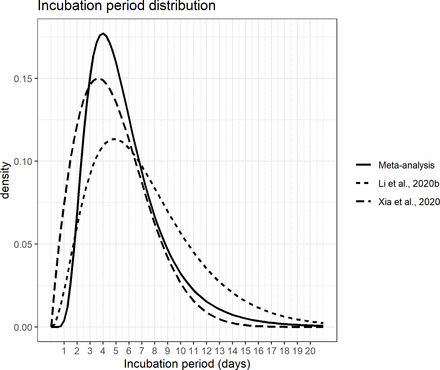
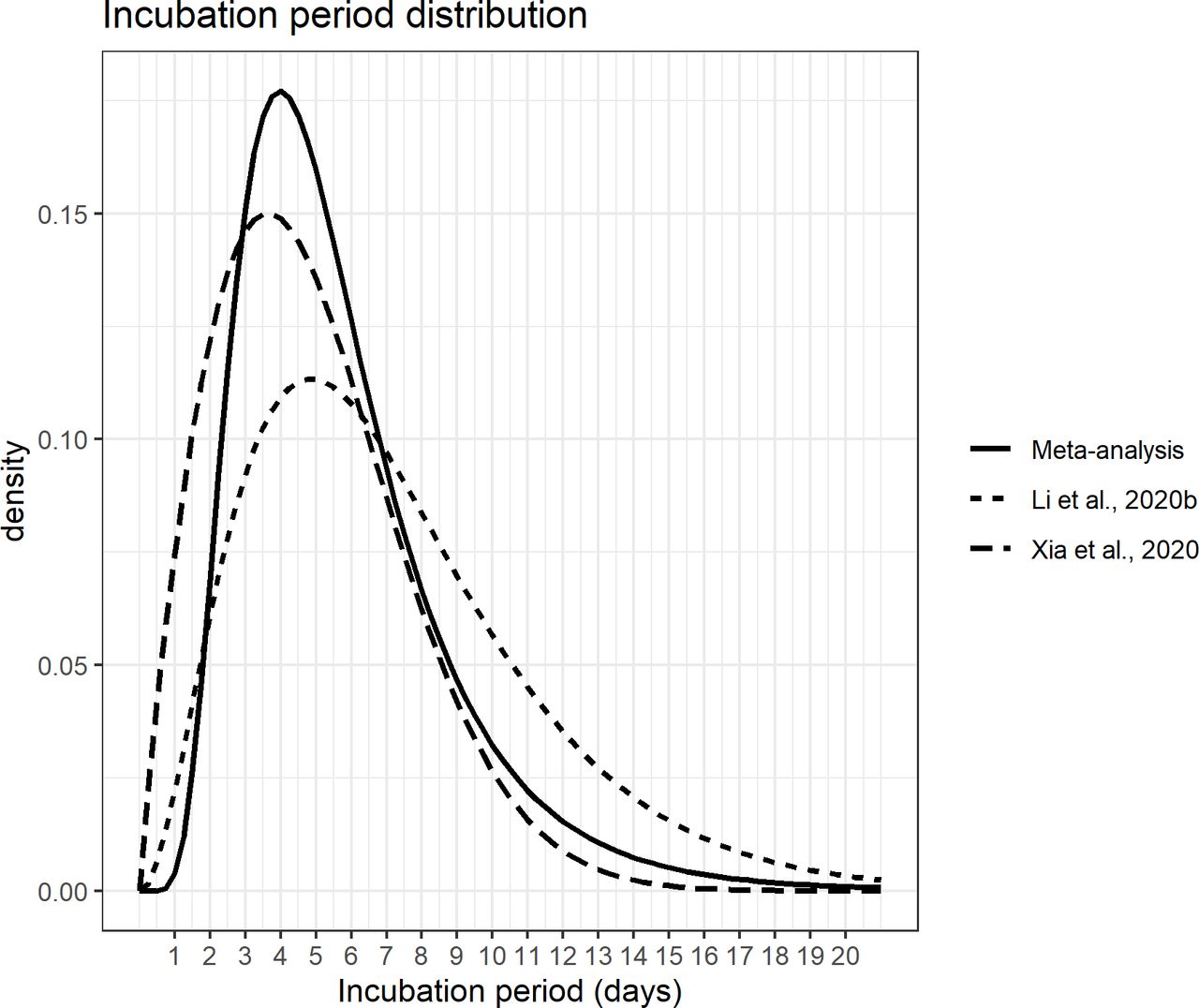{kind=link}
由於使用的分布,薈萃分析中未包括潛伏期和研究(n=2)的合並對數正態分布的概率密度函數。
討論
為了本研究的目的,我們將潛伏期定義為從接觸COVID-19到出現症狀的天數。在線補充圖S3顯示了這段時間內影響COVID-19傳播的其他關鍵參數的示意圖。確定潛伏期的研究可能最精確的是在疫情的早期階段,即病原體廣泛傳播之前。26在這個早期階段,可以有把握地確定曝光窗口。大多數研究是通過對從感染中心(武漢)前往另一個在該時間點或在疫情暴發初期沒有感染的國家/地區的旅行者進行分析來實現這一點的。
初步研究中確定潛伏期的問題
根據定義,確定個體潛伏期所需的病例數據需要包括接觸(窗口期)和症狀發作。準確估計這些事件可能很困難。症狀的發生是基於病例回憶,而暴露是根據以下兩種情況確定的:運動史,從而提供了潛在暴露移動之前的窗口,或已知的暴露窗口(從最早到最晚)到確診病例(密切接觸者)。然而,很少能準確觀察到暴露和/或症狀的發生。用於處理這一問題的方法包括將分析限製在暴露窗口可以縮短到較短窗口(如<3天)的患者的數據上;從曝光窗口取一個中間點來確定曝光時間點。另外,林惇等29將剩餘曝光日期作為模型擬合的參數。然而,幾項研究沒有報告在其分析中使用的病例的暴露時間和症狀發作窗口。在許多情況下,這些被描述為“特征良好”的病例隊列,可能隻包括1天的窗口期,然而,如果是這種情況,我們建議未來的研究明確報告。
調查的異質性
在最初的元分析之後,我們決定移除讚助人等34根據綜合估計進行研究。研究發現,與其他估計相比,該研究的估計大幅向右偏移。對該研究的檢查發現,許多患者的暴露窗口很長,這可能會使估計偏高。有趣的是,該研究對暴露窗口明確的患者進行了額外的亞群分析,在這些數據中,平均潛伏期從6.4天下降到4.5天。然而,有趣的是,馬等30.他們將分析局限於接觸窗口期為3天的患者,仍然發現平均潛伏期為7.4天。由於本研究樣本量最大(n=587),因此對對數正態參數的估計有顯著影響。對兩個讚助人重複元分析等34和馬等30.研究剔除了分別為1.58(1.51,1.64)和0.47(0.42,0.53)的結果。這兩項研究都去掉了I2兩個參數的值都降為0%。對應的平均值和中位數分別為5.48天和4.85天。有趣的是,去掉這項研究也增加了對mu值的估計精度。
的弱點和局限性
該方法的缺點之一是我們獨立地提取和分析了對數正態分布的參數。然而,在現實中,參數和它們擬合的初始分布是聯係在一起的。我們無法包括兩項不符合對數正態分布的數據研究。然而,圖6證明了移除這些研究的影響可能很小,因為它們與彙集估計相似,其中一個落在彙集估計的左側,另一個落在右側。理想情況下,我們應該讓分布適合每項研究的原始數據,以一種促進分布在不同研究之間變化的方式。萊斯勒就采用了這種方法等2在回顧急性呼吸道病毒感染時。然而,我們所檢查的研究並不是所有情況下都有原始數據。另一個限製是,本研究中許多論文使用了公開的數據來估計潛伏期。因此,有一個合理的機會是,一些分析至少重用了一些相同的數據。在這些情況下,這些研究不會彼此獨立。最後,由於本研究是作為快速回顧進行的,我們沒有從被排除的研究中尋求原始數據,也沒有尋求翻譯非英文發表的研究。然而,我們提供了一個R Shiny應用程序(https://mcaloon-ucd.shinyapps.io/shiny2/),這有助於測試我們的綜合估計對包含一項新研究的敏感性。該分析表明,我們的彙總估計在很大程度上不受新的估計的影響。嚐試納入一項報告了對潛伏期相當不同的估計的新研究,對總體彙總估計的影響很小。
與流行病學模型研究中使用的值進行比較
值得注意的是,我們的元分析的參數值比以前在建模研究中使用的參數值略高。例如,弗格森等38引用之前的兩項研究,潛伏期平均為5.1天。29日37meta分析的平均潛伏期為5.8。Tuite等,39另一方麵,引用勞爾的研究,使用了5.0天的潛伏期等.27這個數字(5.0天)是該研究報告的中位潛伏期,27這更接近於我們元分析中估算的5.1天。
外部效度
可以合理地假設,這裏估計的潛伏期在不同人群中應該是相對普遍的:與諸如連續間隔等參數不同,潛伏期隻取決於病毒和宿主之間的相互作用,這在人群中應該是相似的,而不取決於行為因素,如接觸頻率,這可能在不同國家中有所不同。然而,這些數據中可能存在一些偏差,可能會影響其外部有效性:為了準確估計潛伏期,可能會優先選擇特征良好的病例,以減少長時間接觸窗口的影響。這類案件可能傾向於更嚴重的案件。在這種情況下,對潛伏期的估計可能會向下傾斜,因為在受影響更嚴重的個人中,潛伏期可能會更短。此外,這些特征良好的病例(即那些暴露窗口和症狀出現日期具有高度確定性的病例)可能並不能代表所有病例(通常為男性,通常為年輕人)34),強調需要從老年人、合並症患者、婦女和症狀輕微者那裏獲得有關潛伏期的信息。這些發現大多基於對中國患者的研究。雖然一組特定情況下的潛伏期在不同人群中應該是相似的,但可能存在可能影響潛伏期的因素,例如感染劑量,在不同人群之間可能不同(在爆發過程中可能在人群內部),這意味著結果的分布可能在不同人群中不同,或可能在爆發的不同階段不同。不同年齡的人潛伏期也不同。13最後,最近的一項研究也表明,在潛伏期接受手術的患者可能會加速發展為臨床症狀,這表明在潛伏期經曆嚴重壓力的患者可能會更短的時間出現臨床症狀。40
結論
根據現有證據,我們發現潛伏期分布可能是一個對數正態分布,合並mu和sigma參數分別為1.63(1.51,1.75)和0.50(0.45,0.55)。應該注意的是,不確定性在分布的尾部增加(圖4而且表2).采用哪些參數值的選擇將取決於如何使用信息、相關風險和所作決定的可感知後果。相應的平均值為5.8天,中位數為5.1天。一旦獲得進一步的相關資料,將需要重新審議這些建議。因此,我們提供了一個R Shiny應用程序,它可以幫助用戶在獲得新數據時更新這些估算,https://mcaloon-ucd.shinyapps.io/shiny2/
參考文獻
腳注
推特@AndyByrneSci, @MiriamC51755360
貢獻者CM對入圍的研究進行了資格篩選,提取了數據,並對所有作者的輸入進行了分析。ÁC, KH和FB進行了初步的文獻搜索。CM和澳博完成了手稿的初稿。MG和LO回顧了統計方法。所有作者(CM, ÁC, KH, AB, AWB, FB, MC, JG, EL, DM, PW, MG, LO, SJM)閱讀並批準了最終稿件。
資金作者們還沒有從任何公共、商業或非營利部門的資助機構為這項研究宣布具體的資助。
相互競爭的利益所有作者已完成ICMJE統一披露表格www.icmje.org/coi_disclosure.pdf並聲明:提交的作品沒有得到任何組織的支持;在過去3年內,與任何可能與所提交作品有利益關係的組織無財務關係;沒有其他關係或活動可能影響提交的工作。
病人同意發表不是必需的。
來源和同行評審不是委托;外部同行評議。
數據可用性聲明所有與研究相關的數據都包含在文章中或作為補充信息上傳。所進行的meta分析的數據包含在手稿中。
請求的權限
如果您希望重用這篇文章的任何部分或全部,請使用下麵的鏈接,它將帶您訪問版權清除中心的RightsLink服務。您將能夠快速獲得價格和以多種不同方式重用內容的即時許可。