條文本

摘要
目標我們執行和評估德國護理需求評估(CNA)數據與法定健康保險(SHI)索賠數據的記錄鏈接。由此產生的數據集應能夠在後續分析中確定醫療保健中的因素,預測長期護理依賴開始和進入德國養老院之間的時間。
設計使用關鍵變量區域、性別、出生日期和護理水平進行了確定性記錄聯係。在進一步的步驟中,增加了護理依賴的根本原因(《國際疾病和相關健康問題統計分類》,第十版(ICD-10)),以便進行更高層次的區分。在鏈接之前,評估了兩個數據集對這些程序的適用性。鏈接後,對每個階段的結果進行分析,並對由此產生的數據集進行橫斷麵評估,以評估通過該過程產生的偏差。
設置該研究包括來自德國SHI和法定長期護理保險的數據。
參與者研究隊列包括158069名在2006年成為護理依賴者的個體。我們獲得了2006年包括188 935人在內的CNA數據。
結果我們可以將CNAs與原始研究隊列中的66310人聯係起來,對應於42.0%。由於數據缺失,來自兩個聯邦州的記錄無法匹配。在擁有相同屬性的人越多的地方,關聯率就越低。結果數據集顯示,與原始隊列相比,年齡、性別和護理水平存在微小差異。
結論德國SHI索賠數據與CNA數據聯動是可行的。未能建立聯係的主要原因是使用可用標識符的個人之間缺乏區分。由此產生的數據集包含來自衛生服務提供和依賴護理的人的功能狀態的相關信息,適合用於進一步分析,並對代表性進行批判性反映。
- 統計與研究方法
- 公共衛生
- 流行病學
數據可用性聲明
數據可以從第三方獲得,但並不公開。個人數據的使用受到德國聯邦數據保護法和歐盟一般數據保護法的限製。有關資料持有人準許進行研究的機構在研究範圍及期間使用有關資料。數據訪問隻能通過數據持有者獲得。
這是一篇開放獲取的文章,根據創作共用署名非商業(CC BY-NC 4.0)許可證發布,該許可證允許其他人以非商業方式分發、混音、改編、在此基礎上進行構建,並以不同的條款許可其衍生作品,前提是正確引用原始作品,給予適當的榮譽,任何更改都已注明,並且使用是非商業性的。看到的:http://creativecommons.org/licenses/by-nc/4.0/.
數據來自Altmetric.com
本研究的優勢和局限性
這項研究是首次將德國法定健康保險索賠數據與護理需求評估數據聯係起來的研究之一,盡管缺乏唯一的標識符。
一個大的和有代表性的樣本被納入保險執行和評估聯動過程。
三相數據鏈接增加了鏈接記錄的數量以及包含的和相應的屬性的數量。
可用的例程數據缺乏可靠地驗證所執行數據鏈接的準確性的信息。
背景
受影響的人認為進入養老院是不可取的:依賴護理的人更喜歡生活在一個具有高度個人自主權的環境中,這最好是他們傳統的家。1 - 4考慮個人的偏好在醫療保健結果方麵再次被認為是有益的。1雖然關於偏好的知識對於長期護理和住房安排本身的規劃特別重要,但需要推進防止護理依賴者製度化的努力。
除了家庭護理情況的影響外,健康狀況被發現是護理依賴者製度化的一個重要預測因素。認知障礙和功能障礙顯示了預測養老院入院的更有力證據,而中風、高血壓、呼吸係統疾病或關節炎等單一診斷的存在對機構的影響並不是決定性的。5
在德國,醫療保健和長期護理保險是強製性的。大約90%的人口通過保險基金提供的法定長期護理保險(LTCI)和法定健康保險(SHI)投保。私人保健和長期醫療保險的替代選擇有限,主要取決於就業狀況和收入。6SHI和LTCI是分開的,但主要由相同的保險基金和公司提供。
SHI根據醫療需要提供實物服務,包括住院和門診醫療、處方藥、醫療康複、物理和職業治療,不設上限,但遵循“充分、適當和高效”的原則。6長期護理中心為需要護理的人提供實物服務和現金福利。護理需求評估(CNA)是在要求和懷疑長期護理依賴時進行的,當一個人的病情發生相關變化時進行。它可以由任何人發起,需要受影響的人或他們的法定監護人的同意。長期醫療服務公司已將CNA委托給德國醫療服務供應商(MDK)的區域醫療服務。共有15個區域的醫療谘詢機構,隸屬於德國醫療服務基金協會的醫療谘詢服務機構,該機構在國家一級協調其工作。直到2016年,評估結果一直被SHI基金用於決定1至3級護理水平的津貼,其中對一個人預計每天需要的平均護理時間進行分類。2017年,CNA進行了改革,長期ci福利的資格基於五個護理等級,7個人能力和資源發揮著關鍵作用。護理級別的授予可追溯至申請之日。每個護理級別和選定的服務類型(實物、現金或兩者的組合)的福利金額都有上限。7因此,長期醫療保險的設計並不一定涵蓋護理依賴的所有費用。
通過長期護理機構提供的長期護理服務及其資金,與通過健康保險提供的保健服務及其各自的資金是分開的。8由於SHI公司定期提供LTCI,兩個部門的索賠數據可以在一個地方獲得。SHI的實物服務基於《國際疾病和相關健康問題統計分類》第10版(ICD-10)的診斷,程序代碼(住院患者的手術和程序分類係統,門診護理的統一價值量表)和提供的藥物(解剖治療化學分類)進行高粒度計費。然而,來自LTCI的索賠數據隻提供了非常有限的關於護理安排的見解,因為它們隻包括護理水平、在養老院或社區住所的居住情況以及實物服務和現金福利的數量。
相比之下,CNA通常在需要護理的人在場的情況下進行,並在他們的家中進行。在評估中,申請人的功能和認知狀況以及住房、生活和護理安排都被考慮在內。9因此,在CNA期間收集的信息為影響他們生活選擇的條件提供了不可或缺的見解。因此,這些評估與SHI索賠數據相結合,顯著增加了了解與製度化之前的時間相關因素的可能性。
這些預測因素包括有關生活和住房條件、依賴照護者的功能狀況以及他們的住院和門診保健和康複史的信息。由於沒有包含這些信息的綜合數據集,我們不得不將來自德國主要SHI基金AOK的全國索賠數據與MDS持有的CNA數據結合起來。由於這兩個數據集來自不同的數據持有人,並且不包含一個共同的唯一標識符,因此必須結合幾個單獨的屬性來連接個人記錄以進行進一步分析。
本文描述了在沒有唯一標識符的情況下連接兩個數據集的過程。目的是(1)評估兩個數據集的可比性,(2)執行和描述數據鏈接,(3)評估鏈接結果的有效性和合理性,特別考慮將選擇偏差引入鏈接數據集,(4)從而獲得一個數據集,允許在後續分析中評估依賴護理的人在住房和生活條件方麵的製度化,以及他們所接受的醫療保健。10 - 13
方法
本研究展示了在準備回顧性封閉隊列研究時使用次要數據進行的記錄關聯的橫斷麵結果,收集的次要數據主要不是用於科學用途。為了實現以入住療養院為主要終點的最長11年隨訪,我們隻納入了2006年在家中生活並有資格享受長期ci福利的研究隊列中的個體。個人必須在今年至少65歲。兩個數據集來自各自的數據持有者,他們也是研究聯盟的合作夥伴。AOK科學研究所提供了2006-2016年研究隊列中所有人的索賠數據。MDS提供了2006年的CNA數據。兩家機構的數據保護官員都認可這項研究,包括兩個數據集的聯係。我們遵循已發布的質量保證建議14和報告15在適用的情況下進行數據關聯研究,並將報告與加強流行病學觀察性研究報告的橫斷麵研究聲明相一致。16
SHI索賠數據
2006年,所有65歲以上、由全國17家德國AOK保險公司之一投保、成為護理依賴者並從LTCI中獲得福利的個人的SHI索賠數據共計158 069人,代表了研究隊列。隻包括2006年每個季度在AOK投保的個人,他們全年都幸存下來,並且在這一年沒有搬進養老院。數據包含整個個人住院和門診醫療史,包括診斷和程序、藥物治療、康複服務、物理治療、職業治療、言語和語言治療、足療、長期護理福利類型(家庭護理或療養院護理)以及聯邦州、郵政編碼、出生日期和性別的個人數據。
為了進行聯係,我們結合2006年和2007年的ICD-10診斷使用了個人數據和護理水平。由於有證據表明,索賠數據中門診診斷的編碼質量可能缺乏有效性,17-21我們隻使用那些被認為是高效度的診斷:對於住院患者的診斷,我們考慮了出院時診斷的ICD-10代碼。門診診斷采用M2Q標準進行驗證。20.這就是說,診斷隻有在最初診斷後的四個季度內至少發生一次,才被認為是有效的。僅根據ICD-10德語修改(ICD-10- gm)標記為確定或身份職位的診斷用於此程序,排除診斷和疑似診斷被省略。
CNA數據
提供的數據包含2006年15個區域MDK之一要求的AOK被保險人的CNAs的所有結果,MDS根據德國LTCI基金協會的統計指南收集了這些數據。對於下薩克森州和不萊梅州,aok保險無法確定。因此,我們為這兩個州提供了所有參加shi保險的人的CNA數據,而不考慮保險基金。
CNA數據集包含以下信息:日常生活活動中的協助需求和所需的協助時間、可用和推薦的治療設備、同居和協助人員、長期護理中心和SHI提供的進一步服務建議以及CNA過程的一般信息。需求評估不僅在首次申請長期保險福利時進行,而且在被保險人提出異議或申請更高的護理水平後也進行重新評估。因此,該數據集可能包含了每個人的多個評估記錄,以及2006年之前接受長期ci福利的人的記錄。因此,這些記錄不符合研究的納入標準,必須在重複數據刪除過程中排除。
在第一步中,我們在2006年通過初步評估確定了個人的重新評估。由於CNA數據中沒有個人標識符,我們必須通過使用可用數據中的適當變量來識別來自同一個人的記錄。我們按地區(14個屬性)、地區SHI標識符(1531個屬性)、性別(2個屬性)、出生日期、評估時機(3個屬性:初次評估、申請更高護理級別後重新評估、反對後重新評估)和評估日期對數據進行分類。當MDK區域、SHI標識符、性別和出生日期相等,並且重新評估表明與先前評估後授予的先驗護理水平相同時,假設記錄屬於單個人。
2006年無法確定初始評估的個人評估隨後被排除在外,因為他們不符合研究的納入標準。此外,我們排除了所有在2006年年齡小於65歲的個體、評估後未獲得護理水平的個體、2006年之前擁有護理水平的個體,以及根據項目納入標準申請療養院護理長期ci福利的個體。為了與SHI索賠數據保持一致,我們隻使用了2006年最後一次評估的信息,僅包括當年的最新信息。這導致了188 935個人的CNA數據記錄,用於進一步的處理。
鏈接
我們確定了兩個數據集共有的四個關鍵變量,以確定記錄鏈接:(1)地區,(2)性別,(3)出生日期和(4)護理水平。需求評估數據還包含一個單獨的(5)護理依賴的潛在原因,編碼為ICD-10。這個屬性可以在SHI索賠數據的住院和門診診斷中找到,從而產生了具有一對多關係的第五個變量。
這些變量的屬性必須轉換為一個共同的名稱。這包括壓縮來自16個聯邦州的SHI索賠數據中的區域屬性,以適應15個MDK區域。漢堡和石勒蘇益格-荷爾斯泰因以及柏林和勃蘭登堡必須合並,因為每個聯邦州共享一個MDK。北萊茵-威斯特法倫州有兩個獨立的MDK區域,這兩個區域也合並了,因為來自SHI索賠數據的信息沒有提供這種分配。這導致了14個區域的聯動。此外,巴伐利亞州和巴登-符騰堡州的出生日期和月份在CNA數據中缺失,在兩個數據集中都設置為1月1日。這樣就可以避免過早排除這些觀察結果,並保留成功聯係的可能性。
由於12.6%的評估中護理依賴的根本原因無效或未填寫,並且由於評估中提供醫學診斷不是強製性的,其有效性不確定,我們選擇了逐步方法。由於我們期望兩個數據集包含相同的個體(在CNA數據中有來自不來梅和下薩克森州的多餘記錄),這可能不一定可以通過關鍵變量進行區分,當匹配不唯一時,我們在以下步驟中添加了更詳細的變量。該過程描述在圖1.
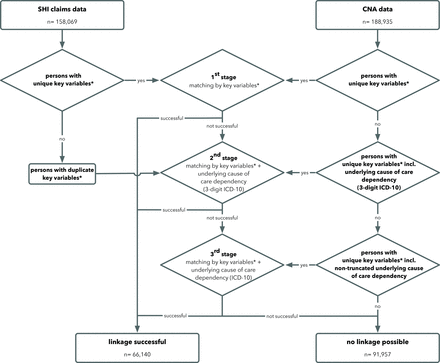
聯動流程流程圖。*關鍵變量:地區、性別、出生日期、護理水平。CNA,護理需求評估;法定健康保險;《國際疾病和相關健康問題統計分類》,第十版。
在第一階段,我們從標識符區域、性別、出生日期和護理水平所特有的各自數據集中提取所有觀察結果。隻有當匹配不明顯時,即至少一個數據集中的一個或多個個體共享相同的標識符,我們才將它們傳遞到第二階段。
在第二階段,我們通過將護理依賴的潛在原因截斷為3位ICD-10作為鏈接變量,將在第一階段中沒有唯一鏈接或沒有按地區、性別、出生日期和護理水平區分的個體聯係起來。我們進行了截短,以考慮到我們的左截短索賠數據在可用診斷和前者(不可用診斷)中存在微小變化的可能性,並考慮到CNA中ICD-10轉錄的微小不準確性。我們考慮了兩個相關的記錄,當前四個變量在兩個數據集中是相同的,並且護理依賴的根本原因在2006年或2007年的SHI索賠數據中作為有效診斷出現(見上文)。隻有唯一鏈接的記錄被認為是成功的,也就是說,隻有來自CNA數據的一條記錄鏈接到SHI索賠數據中的一條記錄。重複的鏈接記錄被傳遞到鏈接過程的第三階段。
第3階段等同於第2階段,除了護理依賴的根本原因ICD-10沒有被截斷。這進一步增加了具有所有其他共同屬性的個體之間的區別。在此階段沒有唯一分配的記錄被認為是不可鏈接的。
統計分析
最初,我們檢查了所提供的兩個數據集的社會人口學屬性。為了跟蹤鏈接過程,我們使用工作數據集進行了臨時描述性分析。為了最終評估關聯成功,我們使用了總結和描述性統計數據,並將關聯與非關聯觀察數據和基礎隊列按性別、年齡組、聯邦州和護理水平進行了比較。
此外,我們以這些相同的屬性為自變量,以聯動成功為因變量,進行多元邏輯回歸。我們報告了每個屬性的or和95% ci。觀察數量最多的類別被用作參考。
為了可信度檢查,我們檢查了SHI索賠數據中診斷的時間順序,以及作為護理依賴的根本原因的診斷。采用SAS軟件V.9.4進行聯動分析。22
患者和公眾參與
患者或公眾沒有參與這項研究的設計、實施、報道或傳播計劃。
結果
兩個數據集的關鍵人口統計數據顯示在表1.與SHI數據相比,CNA數據中超過30,000個觀察值可能歸因於不萊梅和下薩克森州非aok保險個人的評估。此外,每個聯邦州的統計數字都是可比較的,除了萊茵蘭-普法爾茨州在CNA中的記錄是SHI索賠數據的兩倍,漢堡和石勒蘇益格-荷爾斯泰因州的記錄相反,原因不明。性別、年齡和護理水平之間的相對分布顯示兩個數據集之間隻有微小的偏差。
聯係過程
根據MDK地區、性別、出生日期和護理水平,我們發現了99571個獨特的CNAs,而SHI索賠數據中的77782個記錄也符合這些標準。其中50 970人可以明確地相互分配,相當於整個隊列的32.2%。剩下的記錄被傳遞到第二階段。
將護理依賴的潛在原因截斷為3位ICD-10到關鍵變量地區、性別、出生日期和護理水平,我們發現97957個評估在剩餘的CNA數據集中唯一可識別。其中,68625個評估可與AOK數據集中的107099個個體相關聯。然而,在兩個數據集中,兩個觀測值之間隻有13 816個匹配是不同的,且存在一對一的關係。其餘的結果是一對多或多對多匹配,因此在不同的個體之間沒有區別。根據SHI數據定義的研究隊列中,完全匹配的比例為8.7%。在關鍵變量出現重複的地方,觀察被傳遞到第三階段。
在第三階段,應用了與第二階段類似的程序,但使用了未刪節的護理依賴的根本原因ICD-10。在CNA數據中的85011個評估中,有13146個可以與AOK數據集中剩餘的93283個個體相關聯。其中,1315例為一對一匹配,因此在第三階段,0.8%的研究隊列可以額外成功匹配評估。總體而言,41.8% (n=66 101)的研究隊列可以與CNA數據匹配。
聯動效果評價
成功關聯cna的研究隊列中AOK保險的比例顯示在表2.對於巴伐利亞州和巴登-符騰堡州這兩個缺少出生日期和月份的州,相關觀測數據的比例接近於零。漢堡和石勒蘇益格-荷爾斯泰因州的比例也很低,為20.2%。比例最高的是薩爾州(74.4%)和不來梅州(73.6%),這是德國最小的兩個聯邦州。第二階段的相關比例在人口較多的州更高,北萊茵-威斯特法倫州高達16.8%。第三階段的額外匹配在每個地區都低於2%。
從性別差異來看,我們發現女性的整體成功率較男性低,占隊列的近三分之二(表3).在第二和第三階段添加護理依賴的潛在原因導致女性比男性更匹配,盡管不能彌補男性整體更高的聯係率。
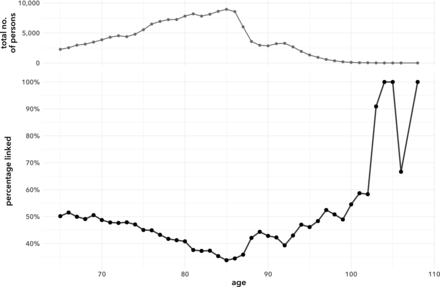
年齡相關的聯係率在上、下年齡邊界上較高,66歲人群為51.5%,108歲人群為100.0%圖2).85歲的發病率最低,為33.8%,也是隊列中發病率最高的年齡。圖2顯示了基於年齡的數據中出現的個體數量與聯動成功之間的反比關係。同齡人口越少,連鎖概率越高,反之亦然。這種關係的Pearson相關係數為−0.67。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
成功連接的個體百分比和數據集中按年齡劃分的個體總數。數據:通過SHI索賠數據定義的研究隊列(n=158 069)。法定健康保險。
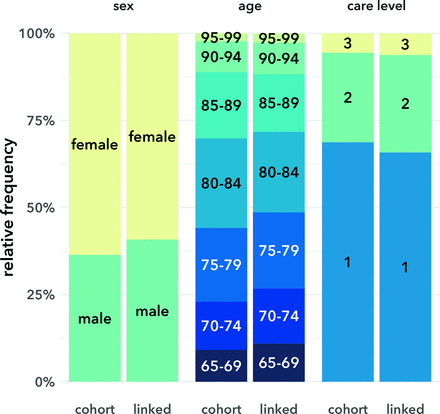
圖3介紹了與基於SHI索賠數據的研究隊列相比的鏈接數據集的結果組成。由於前麵提到的差異鏈接率,兩個數據集之間一些類別的相對頻率有所不同。鏈接數據集的大失真並不明顯。
{kind=link}
{kind=link}
研究隊列與關聯數據集數據的社會人口學組成比較:隊列:通過SHI索賠數據定義的研究隊列(n=158 069);關聯:成功關聯護理需求評估的研究隊列(n= 66101)。法定健康保險。
為了驗證和合理性檢查,我們進一步檢查了由CNA中MDK編碼為ICD-10診斷的護理依賴的根本原因與來自SHI索賠數據的住院和門診診斷之間的關係。對於那些在第一階段聯係的個體(不考慮護理依賴的根本原因),我們審查了從CNA數據中也可以在SHI索賠數據中找到的有效診斷的比例。我們發現,在CNA數據中ICD-10診斷有效的個體中,57.0%的人在門診和住院SHI索賠中至少出現過一次相同的診斷。在CNA之前或之後的四個季度內,56.3%的診斷至少被編碼一次,43.2%的診斷至少被編碼兩次。第一次診斷大多發生在評估之前,66.4%的第一階段相關個體診斷有效。另外25.4%發生在CNA季度。
我們對第二階段和第三階段的個體重複了這一分析,發現61.1%的個體在第一次評估前4個季度進行了診斷,26.4%的個體在評估發生的同一季度進行了診斷。
成功聯動的決定因素
為評估促成成功聯係的個別因素,以性別、護理水平、居住地區和年齡組為自變量進行多變量logistic回歸。結果顯示在表4.我們發現,男性成功連接的幾率是女性的1.5倍。與護理1級相比,護理2級的個體與CNA數據的關聯幾率略高(OR=1.25),而護理3級的個體與CNA數據的關聯幾率略低(OR=0.92)。考慮到地區,我們發現巴伐利亞州和巴登-符騰堡州的or約為零,與北萊茵-威斯特伐利亞地區相比,這兩個地區的出生日期在數據中缺失,由於缺乏獨特性,幾乎沒有觀察結果可以聯係起來。漢堡的OR也大幅降低至0.21。來自下薩克森州的個體成功連接的幾率略低(OR=0.78)。不萊梅州(OR=2.60)和薩爾州(OR=2.63)的連鎖幾率顯著提高。其餘7個地區的OR值在1到2之間,每個地區都與北萊茵-威斯特法倫州相比。在年齡組方麵,我們發現幾乎所有年齡組的成功連接幾率都高於病例數量最多的80-84歲年齡組。唯一的例外是85-89歲年齡組,與參照組相比沒有統計學上的顯著差異。 Especially in the older age groups of 95 years and above, which have considerably lower numbers of insured, the OR is elevated with an up to 5.43-fold chance of linkage for 100–104 years. For the oldest age group of 105 and above, no statistically significant difference could be found.
討論
在本文中,我們描述了德國SHI索賠數據與CNA數據的確定性記錄鏈接的傳導。由於在兩個數據集中都缺乏通用和唯一的個人標識符,我們被限製在四個關鍵變量上:地區、性別、出生日期和護理水平。此外,我們可以從CNA數據中添加護理依賴的根本原因,編碼為ICD-10-GM,這應該與SHI索賠數據中存在的診斷相對應。在逐步鏈接過程之後,我們可以在兩個數據集之間實現中等程度的匹配,在20.2%和74.4%之間,在聯邦州之間有所不同。因此,改進的潛力是明顯的,因為我們期望在應用研究納入和排除標準後,兩個納入的原始數據集都是完整的,並且包含相同的個體。數據集之間的偏差可能隻能通過錯誤或缺失的數據來解釋,或者由於缺乏文檔或對數據的理解而導致標準的不正確應用。在這項研究中,前者出現在巴伐利亞州和巴登-符騰堡州,那裏的出生日期和月份都不存在,後者是由於未能從MDS數據集中僅選擇不萊梅和下薩克森州投保的AOK,在那裏無法進行這種區分,因為SHI基金的標識符似乎與記錄的方案不匹配。兩個數據集的社會人口學組成在很大程度上具有可比性,並支持數據用於數據鏈接的適用性,盡管必須嚴格反映結果數據的代表性,以便進一步使用。
正如對鏈接結果的評估所表明的那樣,成功率特別有限,因為可用的關鍵變量不足以區分數據集中的所有個體。當更多的個體擁有相同的屬性時,這在較低的連鎖概率中可見。據我們所知,德國隻有一項研究與可比數據進行了數據聯動。23本研究僅使用了聯邦黑森州的數據,並實現了75.8%的成功鏈接CNA的比例。與黑森州58.5%的人相比,我們可以鏈接到CNA數據,較高的數量可能歸因於作者能夠使用的額外鏈接變量郵編和評估數據,而他們隻包括年齡,而不是本研究中的整個出生日期。考慮到由於人口變化和長期醫療保險改革,依賴護理的人數預計會增加,7在未來的研究中,提出的精確方法的結果可能會導致更低的鏈接率,因為當更多的人擁有相同的有限屬性集時,個體之間的區分能力就會降低。
由於記錄鏈接受到社會人口學屬性的影響,這對最終的組合數據集產生了影響,對於這些屬性和其他屬性的原始數據來說,該數據集可能不具有代表性,這有助於成功的鏈接。在我們的數據集中,我們確實發現女性以及85歲左右的女性比例偏低。然而,這隻導致了頻率分布的輕微失真。最大的絕對變化在5個百分點以下,原始數據中女性占63.6%,關聯數據中女性占59.2%。在多變量分析中,這些扭曲表現得更為明顯,因為個人成功記錄聯係的機會在很大程度上取決於他們的社會人口學屬性。由於不同的屬性增加了成功聯係的機會,對於護理依賴的根本原因,可以預期對代表性的類似影響,罕見疾病的代表性可能過高,而更常見的疾病(如癡呆症)的代表性不足。
考慮到這些結果,必須反映關聯數據集的代表性,並將其納入進一步的分析。基礎項目的主要成果被定義為護理依賴人群的製度化。後續的分析10 - 13關注醫療保健的決定因素和個人的護理安排對首次出現護理依賴後入住養老院的風險。通過記錄鏈接引入的選擇可能會損害這些分析的有效性。在這裏,我們看到第二和第三階段的不匹配主要歸因於與可用的鏈接變量缺乏區別。兩個具有相似社會人口學屬性的個體的存在不應該與製度化的可能性相關聯。然而,最終數據集中男性的比例高於女性,這可能會影響後續分析與養老院入院相關的外部有效性。因此,根據成功的記錄鏈接的已知決定因素進行分層分析,或將各自的變量作為推斷統計中的協變量。由於巴伐利亞州和巴登-符騰堡州的觀測數據幾乎沒有匹配,因此在進一步的分析中需要排除這些州,這將影響我們對整個德國數據的代表性。必須進一步強調這一點,因為健康保險基金的社會人口統計學差異也是眾所周知的。24 - 26日
提高可鏈接記錄的比例的一種常用方法是概率記錄鏈接,它不僅依賴於特征的奇異組合的存在,而且考慮到兩個觀測數據是否比其他觀測數據具有更高的屬於同一個體的概率。27護理依賴的潛在原因為本研究提供了最有希望的機會。根據SHI索賠數據中診斷編碼的頻率,並假設它應該發生在cna之前或同時(因為確定醫學診斷不是評估的重點),如果滿足這些標準,應該有更高的匹配概率。在本研究中,我們忽略了這種方法,因為在CNA之前,我們沒有所有個人的SHI索賠數據。特別是在第二或第三階段的患者中,隻有12.5%的人在CNA之後第一次進行了診斷編碼,這一事實強調了這一點,因為CNA的預期工作流程將從現有的醫療文件轉移。此外,在納入的個體中,隻有57.0%的ICD-10診斷為評估的護理依賴原因也出現在他們的SHI數據中,在進一步使用之前,應檢查這些診斷的有效性。先前的研究表明,由於各種原因,特定診斷的編碼質量受損,例如當它們對報銷沒有影響時。21
基於所提出的結果,我們認為數據鏈接有效,但存在上述區域代表性和方法學上的限製。進一步的驗證可以包括檢查SHI索賠數據的診斷和在CNA中調查的功能狀態,例如,在沒有輔助或個人支持的情況下,一個四肢癱瘓的個體可能無法自行移動。然而,這種驗證隻適用於非常小的一部分個體,因此,需要確定多個這些合理性檢查。
結論
雖然來自兩個數據集的所有觀測數據中不到一半(預計包含相同的個體)可以鏈接在一起,但我們認為這是一個很好的結果,因為兩個數據集都缺乏唯一或高度不同的標識符。如果沒有唯一標識符,數據鏈接的具體過程很大程度上取決於可用的數據。因此,在處理輔助數據時,特別是在執行記錄鏈接時,關於數據起源的知識是必要的,其中變量和屬性與來自不同來源、通過不同過程、用於不同目的的數據隻是表麵上相同。在來自德國社會係統的數據中存在一個全麵的唯一標識符,適合並可用於科學目的,有助於提高數據質量和更有效的研究。
數據可用性聲明
數據可以從第三方獲得,但並不公開。個人數據的使用受到德國聯邦數據保護法和歐盟一般數據保護法的限製。有關資料持有人準許進行研究的機構在研究範圍及期間使用有關資料。數據訪問隻能通過數據持有者獲得。
倫理語句
患者發表同意書
倫理批準
不適用。
致謝
我們要感謝德國法定健康保險基金協會醫療谘詢服務處和德國法定健康保險基金會科學研究所提供的數據,以及他們在數據使用方麵的專業知識和支持。
參考文獻
腳注
貢獻者DP構思了上級研究項目並申請資助。DD進行數據預處理和記錄聯動,分析結果並撰寫稿件。DP、DD、KS和SS為聯係的概念化作出了貢獻,並就數據的來源和處理提供了專門知識。DD、KS、SS、KW-O、DP對最終稿進行了大量修改、批改和批準。DD作為擔保人。
資金這項工作得到了德國聯邦聯合委員會(Gemeinsamer Bundesausschuss, G-BA)的支持,資助號為01VSF16042。
相互競爭的利益沒有宣布。
患者和公眾參與患者和/或公眾沒有參與本研究的設計、實施、報告或傳播計劃。
出處和同行評審不是委托;外部同行評審。