條文本

摘要
目標調查最近的一項係統綜述和網絡薈萃分析的結論(Cipriani等),抗抑鬱藥比安慰劑對成人抑鬱症更有效的說法得到了證據的支持。
設計用薈萃分析對係統綜述進行再分析。
數據源Cipriani在係統評價中報道了522項試驗(116 477名受試者)等還有其中19項試驗的臨床研究報告。
分析我們分別使用Cochrane手冊的偏倚風險工具和分級推薦評估、發展和評價(GRADE)方法來評估偏倚風險和證據的確定性。使用兩兩亞組薈萃分析估計若幹研究特征和發表狀態的影響。
結果在Cipriani的係統綜述中,抗抑鬱藥證據基礎的幾個方法學局限性要麼沒有被認識到,要麼被低估了等。在研究者評定的抑鬱症狀量表上,采用“安慰劑磨合”研究設計的試驗中,抗抑鬱藥與安慰劑的效應量高於不采用安慰劑磨合設計的試驗(p=0.05)。已發表的試驗中抗抑鬱藥的效應量高於未發表的試驗(p<0.0001)。結果數據由Cipriani報告等19項試驗中有12項(63%)與臨床研究報告不同。根據GRADE,由於高偏倚風險、證據的間接性和發表偏倚,安慰劑對照比較的證據確定性應該非常低。抗抑鬱藥和安慰劑在17項漢密爾頓抑鬱評定量表(範圍0-52分)上的平均差異為1.97分(95% CI 1.74至2.21)。
結論證據並不支持關於抗抑鬱藥對成人抑鬱症的益處的明確結論。目前還不清楚抗抑鬱藥是否比安慰劑更有效。
- 成人精神病學
這是一篇根據知識共享署名非商業(CC BY-NC 4.0)許可發布的開放獲取文章,該許可允許其他人以非商業方式分發,重新混合,改編,構建此作品,並以不同的條款授權其衍生作品,前提是正確引用原始作品,提供適當的信譽,指出任何更改,並且非商業性使用。看到的:http://creativecommons.org/licenses/by-nc/4.0/。
來自Altmetric.com的統計數據
本研究的優勢和局限性
提供的經驗證據表明,抗抑鬱藥治療抑鬱症的證據基礎中有多少偏差和方法局限性影響抗抑鬱藥的表觀效應大小。
與安慰劑相比,“安慰劑磨合”研究設計對抗抑鬱藥表觀效應大小的影響首次得到了估計。
我們報告了抗抑鬱藥與安慰劑的效果估計,作為研究者評定的漢密爾頓抑鬱評定量表的平均差異,以提供一種容易被患者和臨床醫生解釋的結果測量。
在可能的情況下,我們比較了Cipriani報告的數據等根據我們之前從歐洲藥品管理局獲得的臨床研究報告,對完全退出和因不良事件而退出的結果進行了比較。
我們的分析依賴於Cipriani在係統綜述中報告的數據等我們沒有進行單獨的文獻檢索和數據提取;考慮到我們已經確定的方法學局限性,可靠的評估需要基於臨床研究報告和個體患者數據。
介紹
世衛組織估計,全球有3億人患有抑鬱症,使抑鬱症成為全世界致殘的主要原因。1在丹麥,2016年,所有25歲及以上的成年人中有10%在接受抗抑鬱藥治療。2在美國,2014年有13%的12歲及以上的人在接受治療,這使得抗抑鬱藥成為三種最常用的藥物之一。3.據估計,2016年英國國家醫療服務體係(National Health Service)在抗抑鬱藥處方上花費了2.67億英鎊。4因此,指導抑鬱症臨床治療的研究對數百萬人和國家經濟具有潛在的重要影響。
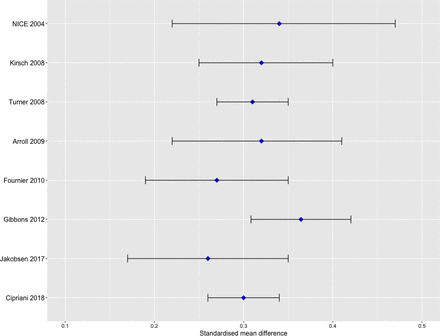
Cipriani最近對抑鬱症抗抑鬱藥的網絡薈萃分析等5是迄今為止最大的關於抗抑鬱藥物的薈萃分析,包括研究和參與者。它特別旨在通過比較21種治療成人抑鬱症的抗抑鬱藥物,為臨床指南、患者、醫生和政策製定者提供信息。該綜述的主要結果是“反應率”(定義為在觀察者評定的抑鬱量表上至少減少50%的參與者人數)和總體輟學率。次要結果是抑鬱症狀評分、“緩解率”(定義為觀察者評定的抑鬱評分低於某一閾值的參與者人數)和因不良事件而退出。Cipriani等發現所有21種抗抑鬱藥都比安慰劑更有效,而隻有兩種藥物與安慰劑相比輟學率更低。基於這些發現,他們5根據反應率和總體輟學率對抗抑鬱藥進行排名,並得出結論,抗抑鬱藥比安慰劑對成人重度抑鬱症更有效。他們發現症狀得分的改善與之前的薈萃分析非常相似(圖1),其中一些研究得出結論,抗抑鬱藥的益處值得懷疑。6 - 9這篇評論得到了媒體的廣泛報道,很大程度上認為它最終消除了人們對抗抑鬱藥療效的懷疑,10 11一些作者在媒體上強烈傳達了抗抑鬱藥有效的信息,10補充說,好處大於副作用。11
{kind=link}
{kind=link}
先前的薈萃分析報告了抗抑鬱藥與安慰劑在成人中的效應大小。數據以95% ci的標準化平均差異報告。好2004年6:選擇性血清素再吸收抑製劑。櫻桃酒20088“新一代”抗抑鬱藥。特納2008年9所有抗抑鬱藥。Arroll 200941:初級保健中用於抑鬱症的抗抑鬱藥。數據代表三環抗抑鬱藥和SSRIs與安慰劑的合並估計,固定效應模型。弗爾涅201042所有抗抑鬱藥。數據代表三組嚴重程度(輕度至中度、嚴重、極嚴重)的彙總估計,固定效應模型。吉本斯201243氟西汀和文拉法辛。Jakobsen 20177:選擇性血清素再吸收抑製劑。平均變化分數的效應量。Cipriani 20185所有抗抑鬱藥。選擇性血清素再攝取抑製劑。
抗抑鬱藥物的試驗有很多方法學上的局限性,12其中許多已經被承認了幾十年。13旨在告知臨床實踐使用抗抑鬱藥治療抑鬱症的研究必須認識到這些局限性。我們已經解決了Cipriani中偏倚風險評估的一些局限性等審查。14然而,考慮到奇普裏亞尼的潛在影響等的審查,5我們在這裏的目的是提供一個更全麵的評估。具體而言,我們希望調查證據庫的方法學局限性是如何解決的,綜述對納入試驗偏倚風險的評估和對證據確定性的評估是否適當,是否遵循作者所述的方法,以及結論是否得到證據的支持。此外,我們旨在通過使用Cipriani報告的數據,為這些方法局限性的影響提供經驗證據等。5
方法
數據收集
我們從在線增刊中提取了綜述的偏倚風險評估和描述性數據,並將數據轉換為Microsoft Excel格式。我們下載了在線數據集5並將文件合並用於統計分析。
我們將納入的試驗與我們之前在2010年從歐洲藥品管理局獲得的臨床研究報告進行了交叉參考。15我們將臨床研究報告中報告的總輟學率和不良事件導致的輟學率與Cipriani報告的數據進行了比較等。5
統計分析
在Microsoft Excel中進行描述性分析。我們使用統計軟件R V.3.4.3進行基於反方差法的隨機效應薈萃分析,並將效應大小計算為標準化平均差異(SMD)作為Hedges ' g,具有相應的95% CI。不同研究中觀察到的幹預效果之間的差異程度用Tau計算2效應估計中由異質性引起的可變性百分比計算為I2。對於抗抑鬱藥和安慰劑在評分量表上的比較,我們使用了Hartung-Knapp-Sidik-Jonkman方法,因為它比DerSimonian和Laird方法產生的I型錯誤更少。16我們的分析基於來自奇普裏亞尼的參與者人數等的“功效”分析。5在有多個藥物組的研究中,安慰劑組的參與者總數在積極的比較中平均分配,均數和標準差不變。17我們根據Cipriani發表的試驗特征,基於“安慰劑對照”研究設計、讚助和發表狀態,進行了亞組分析等。5
質量評估
我們評估了奇普裏亞尼是否等的偏倚風險評估是按照Cochrane手冊進行的,17如作者所述。5方法的不同之處在於我們比較了Cipriani等5我們根據《科克倫手冊》進行了重新評估。17評估的具體偏倚領域(和偏倚類型)包括序列生成(選擇偏倚)、分配序列隱藏(選擇偏倚)、參與者和人員的盲化(表現偏倚)、結果評估的盲化(檢測偏倚)、不完整的結果數據(損耗偏倚)、選擇性結果報告(報告偏倚)和其他潛在的偏倚來源。17
我們使用了建議分級評估,發展和評估(GRADE)18評價證據確定性的方法,對於係統評價,證據確定性反映了估計效果正確的置信度。GRADE考慮了影響證據質量的五個領域:納入試驗的內部偏倚風險、納入試驗結果的不一致和較大的異質性、外部效度差導致的證據的間接性、效應估計的不精確和廣泛的CIs,以及發表偏倚。18
病人及公眾參與
沒有患者參與研究問題的發展,研究的設計和實施,或結果的解釋。
結果
偏倚風險
隨機序列生成和分配序列隱藏
Cipriani等5在522項納入的試驗中,分別有426項(82%)和460項(88%)在隨機化序列生成和分配隱藏方麵的偏倚風險不明確。其餘試驗偏倚風險較低。在這兩個領域中,偏倚風險高或不明確的試驗可能會報告誇大的效果估計,特別是主觀結果。19Cipriani等沒有描述他們如何評估與隨機化序列生成或分配隱藏相關的偏倚風險,因此我們無法評估他們的方法是否遵循Cochrane手冊中概述的方法。17
參與者、人員和結果評估的盲法
Cipriani等5由於缺乏盲法,沒有使用低、不明確或高偏倚風險的標準Cochrane分類。17他們將513項(98%)研究歸類為至少在三個盲法領域中的一個領域中“聲明-未經測試”,這意味著該試驗被聲明為雙盲,但沒有測試盲法的完整性。雖然這暗示了盲性問題的存在,但它們的分類並不影響偏倚評估的總體風險5而且,未被測試的領域似乎被視為“低偏倚風險”。奇普裏亞尼分類的三個試驗中的兩個等5為了在參與者領域的盲化中具有低偏倚風險,測試了盲化完整性(在線)S1附錄)。在兩項試驗中,盲法可能都有所妥協。抗抑鬱藥的副作用很常見,在隨機試驗中經常顯示誰接受了積極的藥物治療,誰接受了安慰劑。解盲的程度是廣泛的,並導致誇大的效果估計,20.當在安慰劑中加入阿托品的效果更好時,觀察到的效果較小。21考慮到這些問題,所有抗抑鬱藥的安慰劑對照試驗都應該被歸類為至少不清楚,或者甚至可能有很高的偏見風險。
結果數據不完整
Cipriani等將采用適當的歸算方法的試驗評定為低偏倚風險。5使用“不適當”歸算方法的試驗根據幾個任意截斷值進行評級:當兩組之間的退出率不平衡時,定義為頭對頭比較的差異超過5%,安慰劑比較的差異超過10%,它們被評為高風險偏倚。當兩組之間的輟學率不平衡,但總輟學率為20%時,被評為不清楚,如果總輟學率<20%,則被評為低偏倚風險。這種方法與《Cochrane Handbook》不一致,《Cochrane Handbook》強調,不可能製定一個簡單的規則來判斷一項研究是低還是高的消耗偏倚風險,因為偏倚風險取決於幾個因素。17此外,作者沒有考慮輟學的原因,盡管這也是Cochrane手冊推薦的。17
據奇普裏亞尼說等, 121項(23%)試驗存在高消耗偏倚風險,但我們無法重複這些結果。在334次(64%)試驗中,總損失率為20%。用Cipriani定義的截止值等根據Cipriani描述的方法,我們發現202項試驗(39%)的組間輟學率不平衡等5除非使用了“適當的歸責方法”,否則它們本應被評為高風險偏倚。Cipriani等認為最後一次觀測結轉(LOCF)方法不合適,22但他們沒有提供在納入的試驗中使用的歸算方法的數據。因此,我們不能應用奇普裏亞尼等在我們重新評估損耗偏差時,我們的分類。大多數抗抑鬱藥物試驗使用LOCF法,23這可能導致對變異性的低估,錯誤的低p值和對治療效果的高估。24
選擇性結果報告
Cipriani等5判斷522項試驗中402項(77%)為低風險的結果報告偏倚,100項(19%)為不明確風險偏倚,20項(4%)為高風險偏倚。他們的評估是基於綜述的兩個主要結果——反應率和總體輟學率的報告,隻有在兩個結果都缺失的情況下,試驗才被評為高偏倚風險。這與Cochrane手冊不一致,在Cochrane手冊中,建議對所有相關結果進行研究水平判斷。17根據我們的分析,該綜述的三個次要結局——不良事件導致的退出、抑鬱症狀量表測量的抑鬱症狀和緩解率,分別在93項(18%)試驗、98項(19%)試驗和71項(14%)試驗中沒有報道。我們發現共有182項(35%)試驗沒有報告至少一個主要或次要結局,按照《Cochrane手冊》的建議考慮所有相關結局,這些試驗可能被評為高風險偏倚。17選擇性結果報告導致高估幹預措施的益處和低估幹預措施的危害。25
其他偏置域
作者從偏倚風險評估中省略了“其他偏倚”域,盡管它是Cochrane偏倚風險工具的一個組成部分。17該領域的相關偏倚包括基線不平衡和交叉和聚類隨機試驗的設計特異性偏倚風險,根據Cipriani符合條件等協議,22雖然試驗設計在綜述中沒有具體說明。5一些人認為也應該考慮“既得利益”,因為工業讚助的藥物研究比其他研究產生更有利的效果,其機製無法用通常的偏倚域來解釋。26我們通過使用Cipriani分類對讚助的安慰劑對照試驗進行隨機效應薈萃分析,探討了行業讚助是否與更大的效應估計有關等(在線S1附錄)。我們發現,歸類為“讚助”的試驗(SMD為0.27 (95% CI為0.25至0.30,341個比較,207個試驗)的效應量低於歸類為“不明確”的試驗(SMD為0.39 (95% CI為0.25至0.52,12個比較,10個試驗)和“非讚助”的試驗(SMD為0.41 (95% CI為0.31至0.52,37個比較,36個試驗))(三種估計之間的差異p=0.005) (表1)。
總結偏倚風險評估
作者偏離了Cochrane對低、不明確或高風險偏倚的總體風險分類,17通過引入他們自己的“中等”偏見風險類別。如果評估的領域中沒有一個被評為高風險偏倚,三個或更少的被評為風險不明確,他們將試驗分類為低偏倚風險;中度:一個領域被評為高風險偏倚,或沒有一個領域被評為高風險偏倚,但四個或更多被評為風險不明確;所有其他病例都被評為高偏倚風險。5這種方法類似於使用量表將多個項目的分數加起來得出一個總數,這在Cochrane手冊中是不鼓勵的。17相反,《手冊》建議考慮到不同領域的相對重要性進行全麵的定性評估。17作者將522項試驗中的96項(18%)評定為低偏倚風險,380項(73%)評定為中度偏倚,46項(9%)評定為高風險偏倚。我們無法複製這些發現,而且這些努力很困難,因為不清楚如何根據偏倚風險對盲域進行評級。鑒於綜述的五個結果都可能受到所有偏倚風險域的影響,《Cochrane手冊》建議的定性方法包括將具有任何“高偏倚風險”域的試驗分類為總體高偏倚風險。17應用這些標準(Cochrane Handbook,表8.7.a)17在Cipriani等有1項試驗為低偏倚風險,383項試驗(73%)為不明確風險,138項試驗(26%)為高偏倚風險。當我們將我們的分類用於盲域(即,所有安慰劑對照試驗被評為不明確的偏倚風險,以及選擇性結果報告域)時,沒有(0%)低偏倚風險的試驗,261(50%)風險不明確的試驗和261(50%)高風險偏倚的試驗(在線)S1附錄)。如果三個盲域在安慰劑對照試驗中被評為高風險偏倚,而不是不明確的偏倚風險,則沒有(0%)低風險試驗,108項(21%)不明確風險試驗和414項(79%)高風險偏倚試驗(在線)S1附錄)。
發表偏倚
抗抑鬱藥物試驗的發表偏倚普遍存在,並扭曲了證據基礎。9許多行業資助的抗抑鬱藥物試驗仍未發表或報告不充分。9Cipriani等5包括436項已發表的研究和86項未發表的研究,但可能已經進行了多達1000項抗抑鬱研究。13我們根據發表狀態對安慰劑比較進行了隨機效應薈萃分析,發現未發表研究的平均效應大小(SMD 0.15 (95% CI 0.11至0.19,96個比較,57個試驗)低於已發表研究(SMD 0.33 (95% CI 0.30至0.35,294個比較,196個試驗))(兩種估計的差異p<0.0001) (表1)。我們的發現與特納的報告非常相似等9在2008年美國食品和藥物管理局(FDA)注冊的已發表和未發表的抗抑鬱藥物試驗中發現,已發表研究的SMD為0.37 (95% CI 0.33至0.41),未發表研究的SMD為0.15 (95% CI 0.08至0.22)。這表明Cipriani報告的效應大小等5可能由於發表偏倚而被誇大。由於發表偏倚的風險,他們正確地降低了對證據的信心,但估計發表偏倚對其效果估計的影響也是適當的。
試驗持續時間和長期效果
Cipriani等5在4-12周的時間間隔內,盡可能在接近8周的隨訪時間內提取結果數據。5但他們沒有為這一決定提供理由。22常見的臨床做法是開更長時間的抗抑鬱藥。在荷蘭,43%的SSRI(選擇性血清素再攝取抑製劑)使用者接受了15個月或更長時間的治療,27而在美國,68%服用抗抑鬱藥的人服用了2年或更長時間,25%服用了10 - 10年。3.雖然作者承認試驗持續時間短是一個局限性,但應該強調這種短隨訪缺乏臨床相關性,並且應該將證據的可信度在GRADE“間接”領域降低一級。更合適的方法是根據治療時間和隨訪時間提取結果數據,以評估治療效果隨時間的變化。根據Cipriani報告的試驗特征等,5304個安慰劑對照試驗中有12個(4%)持續了10 ~ 12周。然而,我們發現這12項試驗中隻有4項包含不間斷的雙盲、安慰劑對照期,為期12周(在線)S2附錄)。隨訪時間最長的兩項安慰劑對照試驗包括81名參與者,隨訪時間為36周(在線)S2附錄)。隨訪時間短的另一個後果是對嚴重和非嚴重不良事件的低估。28
安慰劑的磨合和已接受治療的患者
安慰劑試驗的設計扭曲了對益處和危害的估計(箱1)。Cipriani等沒有給出安慰劑磨合的明確定義,22但他們將522項試驗中的260項(50%)描述為有安慰劑磨合,182項(35%)試驗不清楚,80項(15%)試驗沒有安慰劑磨合。5我們進行隨機安慰劑對照試驗的薈萃分析顯示使用安慰劑試車設計和發現之間的效應大小不同團體的SMD 0.31(95%可信區間0.28到0.34,221比較,142試驗)與安慰劑試車試驗,SMD是0.29(95%可信區間0.25到0.33,120比較,79試驗),使用安慰劑的爭執還不清楚和SMD 0.22(95%可信區間0.16到0.29,46歲比較,30個試驗)在沒有安慰劑磨合的試驗中(三個估計之間的差異p=0.05)。在沒有安慰劑磨合的未發表試驗的進一步亞組分析中,效應量非常小(SMD為0.08,95% CI為- 0.27至0.11,8個比較,5個試驗)。Cipriani沒有討論安慰劑磨合設計的使用及其影響等。5
“安慰劑磨合”,最小的臨床顯著差異,以及“反應”作為結果。
A.安慰劑的磨合和已經接受治療的參與者的加入扭曲了利益與損害的平衡。
Cipriani等5沒有提供安慰劑磨合的定義,但它通常涉及參與者在隨機化之前接受安慰劑,通常是大約一周後,非依從性參與者和對安慰劑反應良好的參與者(通常稱為“安慰劑反應者”)被排除在試驗之外。已經接受抗抑鬱藥物治療的參與者,包括研究藥物,實際上總是被允許進入試驗,通常所有參與者都在安慰劑的磨合中逐漸減少正在進行的抗抑鬱藥物治療。本研究設計可能通過幾種機製影響安慰劑對照試驗的效果估計和利/弊平衡,這些機製有利於藥物而不是安慰劑:
B.“有效率”缺乏臨床意義。
反應率通常被定義為在隨機臨床試驗中,在一個標準化的抑鬱觀察者評定量表(如漢密爾頓抑鬱評定量表或蒙哥馬利-Åsberg評定量表)上,達到總分減少50%的參與者人數。“無反應”並不一定意味著參與者的狀況沒有改善,而隻是表明改善程度小於50%。“回應者”和“不回應者”之間的差異可能隻有1分。因此,被歸類為無反應的參與者實際上可能表現出實質性的改善。因此,抗抑鬱藥和安慰劑之間反應率的差異並不能說明改善的參與者人數的差異,而隻能說明改善超過任意定義閾值的參與者人數的差異。此外,通過關注超過50%減少閾值的參與者的數量,忽略了在試驗期間條件惡化的參與者。因此,與安慰劑相比,觀察藥物的平均效果估計似乎更有臨床意義。
C.臨床相關差異極小。
Cipriani等據報道,抗抑鬱藥和安慰劑之間的標準化平均差異(SMD)為0.3。52004年,英國國家健康與臨床卓越研究所(National Institute of Health and Clinical Excellence)提出,漢密爾頓抑鬱評定量表(Hamilton depression rating scale)上相差3分,即SMD值為0.5,即為臨床顯著變化。6然而,這種差異是武斷的,並非基於經驗數據。45Leucht等2013年的臨床試驗數據表明,臨床醫生無法檢測到漢密爾頓抑鬱量表降低3分或更少。46其他人解釋了同樣的數據,並認為漢密爾頓量表上7分或更多的變化,對應於SMD至少為0.875,對於臨床醫生來說,檢測到最小的臨床改善是必要的。47我們發現抗抑鬱藥和安慰劑在17項漢密爾頓抑鬱量表(範圍0-52分)上的平均差異,基於奇普裏亞尼等的數據,5是1.97分。
輟學是危害的代表
由Cipriani評估總體輟學率和不良反應導致的輟學率等分別作為“可接受性”和“耐受性”的衡量標準,而抗抑鬱藥的實際危害以及嚴重和非嚴重不良事件沒有被評估。使用總退出率作為衡量總體利弊平衡的指標可能是有意義的,但由於包括已知耐受抗抑鬱藥物和使用安慰劑的參與者所引入的偏見,該結果可能偏向於活性藥物(箱1)。此外,由於沒有對包括侵略、自殺和死亡在內的嚴重危害進行仔細分析,29對於特定的不良事件,該綜述沒有提供平衡利弊的基礎,而這對於知情同意和共同臨床決策以及評估藥物的臨床價值至關重要。抗抑鬱藥的不良反應是常見的,最近一項對131項SSRIs治療抑鬱症試驗的薈萃分析發現,與安慰劑相比,嚴重不良事件的風險增加(OR 1.37;95% CI 1.08 ~ 1.75)。7這可能被低估了,因為131項納入的試驗中隻有44項報告了這些數據7而且,抗抑鬱藥的嚴重危害,包括死亡,通常不會在已發表的論文中報道。30.
除兩種藥物外,抗抑鬱藥的總輟學率在統計學上都沒有顯著低於安慰劑。5然而,Cipriani等可能低估了抗抑鬱藥的總退出率,因為58項(11%)試驗中沒有出現抗抑鬱藥,93項(18%)試驗中沒有出現不良事件導致的退出率。一項基於從藥品監管機構獲得的臨床研究報告(而非已發表的數據)對73項試驗的退出者進行的薈萃分析顯示,服用抗抑鬱藥的參與者退出的人數比服用安慰劑的參與者多12%。31
我們查閱了Cipriani納入的522項試驗中19項的臨床研究報告等的審查。所有19項臨床研究報告均完整報道了總輟學率和不良事件導致的輟學率。與這些數據相比,總輟學率或不良事件導致的輟學率要麼沒有報告,要麼被Cipriani錯誤地報告等在19項試驗中的12項(63%)中:2項試驗未報告總退出率,7項試驗報告錯誤;5項試驗未報告不良事件導致的退出,3項試驗報告錯誤(在線)S1表)。
缺乏與患者相關的結果
在精神科藥物試驗中,很少測量和報告與患者相關的結果,如生活質量和病假。相反,這些試驗主要依賴於研究者評定的症狀評分,盡管也存在自評症狀量表。在一項針對成人抑鬱症的ssri類藥物的係統綜述中,131項試驗中隻有6項報告了生活質量數據7即使是臨床研究報告也是不可靠的,因為有選擇性地報道了這個結果。31對患者來說,無法應付日常活動和藥物的副作用可能比他們的抑鬱情緒更重要32並且在方案中排除了與患者相關的結果22是證據和奇普裏亞尼的主要限製等的總體結論。5
臨床無關的療效結果
網絡meta分析的主要療效指標為有效率(箱1)。這是一個有問題的結果,因為它缺乏臨床相關性,可能會產生臨床有效性的錯覺。33在評定量表上測量結果的二分類會導致統計能力的喪失,並增加假陽性結果的風險34以及虛假誇大的效應值。33因此,方法學家不鼓勵使用這種二分法的結果,當評分量表數據可用時,通常應避免使用這種方法。34這些問題也適用於審查的次要結果緩解率。這是奇普裏亞尼的選擇等5隻報告相對反應率而不報告試驗的絕對反應率的做法受到了批評。35然而,即使是絕對緩解率,其臨床相關性也有限。Cipriani等5沒有解決與“反應”和緩解率相關的問題。
統計學意義與臨床意義
Cipriani等5也報告了症狀評定量表上的SMD,這比二分結果更有意義。33 34他們報告了抗抑鬱藥與安慰劑的總體SMD為0.30(95%可信區間為0.26至0.34),但試驗和比較的數量尚不清楚。5我們發現,在直接兩兩比較中,抗抑鬱藥與安慰劑的總體SMD相似,為0.29 (95% CI 0.27至0.31,390個比較,253個研究)(表1)。這些效應估計在統計上是顯著的,但可能低於可被視為臨床相關的效應(箱1)。我們還計算了在17項漢密爾頓抑鬱評定量表中報告終點或改變得分的試驗的總體平均差異,該量表是在所包括的試驗中最常用的量表(在線)S2表)。在17項漢密爾頓抑鬱評定量表(範圍0-52)上,抗抑鬱藥和安慰劑的平均差異為1.97點(95% CI 1.74至2.21,166項比較,109項試驗)(表1)。漢密爾頓量表的平均差異可能也低於可被視為臨床相關的影響(箱1)。Cipriani等沒有討論他們報告的效應大小的臨床意義。5
討論
我們已經確定了幾個重要的偏差,這些偏差在Cipriani的係統評價中沒有考慮到等。5我們發現,在抑鬱評定量表上,抗抑鬱藥對安慰劑的影響很小,而且可能由於試驗中幾個方法學上的限製而被誇大了。我們首次表明,除了發表偏倚和其他方法學上的限製外,安慰劑試驗設計似乎還會產生誇大的效應量。此外,我們展示了Cipriani報告的結果數據等與臨床研究報告不同,他們的偏倚風險評估沒有遵循Cochrane手冊中概述的方法。最後,我們發現抗抑鬱藥與安慰劑在所有結果評估中的證據的確定性應該非常低。綜上所述,這些證據並不支持關於抗抑鬱藥對成人抑鬱症療效的明確結論,包括抗抑鬱藥對抑鬱症是否比安慰劑更有效。
先前的元分析(圖1)在症狀評分上發現了與西普裏亞尼相似的改善等。5其中一些綜述仔細考慮了方法上的局限性,評估了危害,得出了不同的結論。6 - 8我們找到了奇普裏亞尼等沒有按照Cochrane手冊的規定評估偏倚風險5而且他們的結果是不透明的。雖然作者分享他們的數據應該受到讚揚,但大多數綜述的結果無法被複製,因為基本信息,如每個薈萃分析的納入研究、分組和參與者的數量,都沒有報告。網絡薈萃分析方法可能會帶來一些希望,但僅限於存在明顯有效幹預措施並需要進行排名的領域,並且許多統計選項不應掩蓋對證據的初步批判性評估和結果的清晰呈現。當我們對證據缺乏信心時,對抗抑鬱藥進行排名似乎是一種誤導。有趣的是,我們對症狀評分改善的兩兩薈萃分析得出的結果與Cipriani報告的結果非常相似等。因此,網絡元分析方法的額外好處似乎不清楚。5
我們發現證據基礎主要由短期試驗(12周或更短)組成,沒有證據表明治療超過36周,盡管大多數患者治療多年。3 27此外,在Cipriani的綜述中報告的抗抑鬱藥的明顯效果等5研究者評定的症狀量表測量值很小,可能沒有臨床相關性。觀察性研究還表明,抗抑鬱藥在實踐中的有效性非常低:在大型公共資助的緩解抑鬱症的測序治療方案研究中,4041名入組患者中隻有3%在1年後被認為“緩解”。39根據隨機試驗的臨床研究報告,最近的發現是,服用抗抑鬱藥的參與者比服用安慰劑的參與者更多,31進一步表明,抗抑鬱藥的好處可能不會超過它的危害。
我們的研究結果表明,奇普裏亞尼等的數據5是不準確的,他們的估計可能因此是不正確的,因為他們依賴於公布的數據。我們依賴於奇普裏亞尼的數據可能被認為是一種限製等也沒有進行我們自己單獨的係統文獻檢索和數據提取。考慮到我們已經確定的多種方法學局限性,有必要分析基於臨床研究報告和個體患者數據的數據,以對抗抑鬱藥的利弊做出可靠的評估,因為它們是最可靠的試驗數據來源。40我們的讚助亞組分析也有一些局限性:雖然發現行業讚助的研究比非行業讚助的研究更經常報告有利的療效結果,26我們的分析表明,在研究者評定的抑鬱症狀量表上,工業讚助的試驗報告的抗抑鬱藥的效果估計比安慰劑低。然而,兩個亞組之間存在重要差異,可能導致觀察到的差異(在線)S1圖)。非工業讚助的試驗比工業讚助的試驗更小更老幾乎所有的非工業讚助的試驗都包括在Cipriani中等發表。
我們的研究結果強調,成百上千的抗抑鬱藥安慰劑對照試驗並沒有解決最重要的、與患者相關的問題,即抗抑鬱藥的利弊。盡管人們多年前就知道了這一點,13它並沒有導致研究實踐的變化。認為抗抑鬱藥對抑鬱症有效的錯誤結論可能會阻止抑鬱症患者尋求其他解決方案來緩解病情,例如心理治療和處理心理社會壓力源,並且可能會阻礙此類治療方式的資助和研究。重要的是,這樣的結論也可能導致對提供更好的證據基礎來確定抗抑鬱藥的真正臨床價值的興趣的喪失。
我們的研究有兩個含義。首先是奇普裏亞尼的評論等5它的結論應該被仔細地重新審視。根據我們的研究結果,該綜述不應告知臨床實踐。其次,我們的重新分析強調了對抗抑鬱藥物試驗的實施、報告和解釋方式進行徹底改變的必要性。我們希望醫生、病人、同行和政治家們能夠考慮到我們提出的抗抑鬱藥治療抑鬱症的現有證據的局限性,並共同采取相應的行動。這包括告知患者現有證據的局限性,從而為真正的知情同意提供基礎,並努力為使用抗抑鬱藥治療抑鬱症提供更好的證據基礎。為了得到關於抗抑鬱藥對成年抑鬱症患者的利弊的可靠答案,我們需要對naïve參與者進行大規模的、獨立於行業的、更好的盲法長期試驗,采用與患者相關的結果,而不是排名量表。
致謝
我們非常感謝Luis Carlos Saiz, Pharm D, PhD的寶貴意見。
參考文獻
腳注
貢獻者KM, ASP-M和KB對研究的構思和設計做出了貢獻。KM進行了meta分析。KM, ASP-M和KB分析和解釋數據,起草並嚴格修改手稿,並批準最終版本發表。所有作者都可以完全訪問所有數據,並對數據的完整性和數據分析的準確性負責。
資金這項研究由北歐科克倫中心資助。這項研究的設計、實施、分析和解釋完全獨立於資助來源。
相互競爭的利益沒有宣布。
出處和同行評審不是委托;外部同行評審。
數據共享聲明統計分析的所有數據文件和代碼可從開放科學框架數據庫(https://osf.io/3prz9/?view_only=0012d96af77e435f90e77755f728551a)。
患者同意發表不是必需的。
請求的權限
如果您希望重用這篇文章的任何或全部,請使用下麵的鏈接,這將帶您到版權清算中心的RightsLink服務。您將能夠得到一個快速的價格和即時許可,以許多不同的方式重用的內容。